
ビッグデータを分析するためのインフラ
ここまで8回にわたってギックスのビッグデータ分析体系について説明してきました。今回が本連載の最終回となります。本日は「分析インフラ」についてご紹介します。ビックデータ分析体系の中では以下の赤枠の部分に相当します。
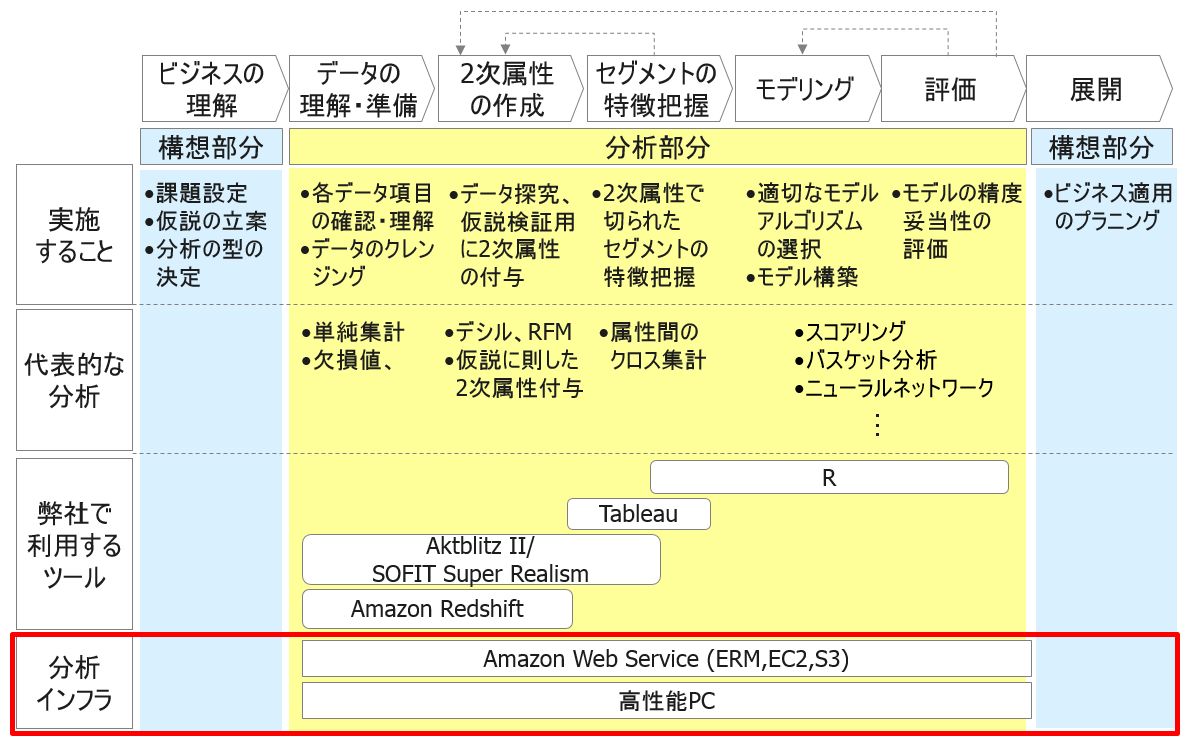
ギックスで分析インフラとして利用しているものには大きく2種類あります。
- 通常のPC
- クラウドサービス
それぞれの環境について説明していきます・
PC上でのビッグデータ分析が可能な時代に
弊社では、通常のPCに、前回ご紹介したAkitblitzIIやTableau、Rといったツールをインストールして利用しています。数千万件規模のデータ分析は、PC上のこれらのツールを連携させながら使います。そこで、前回までで紹介してきた分析プロセスに沿った作業をスムーズに流すことができます。
特にハイスペックなサーバーマシンを用意しているわけではありません。通常のPC上で、これら一連の分析ができる環境が揃うというテクノロジーの進歩は本当にありがたいことです。
更なるビッグデータ分析が可能なAWS環境
一方で更なるビッグデータ、例えば数十億件単位のデータを一気に分析できる環境も我々のような小規模な企業でも準備できます。Amazon Web Services(AWS)に代表されるクラウドサービスです。クラウドサービスとは、従来は利用者が手元のコンピュータで利用していたデータやソフトウェアを、ネットワーク経由で、サービスとして利用者に提供するものです。
AWSの環境下では、非常に大量のデータを分析することができます。例えば弊社の事例で言えば、AWSのRedshiftを利用して、60億件のデータについて、2次属性を作成した実績があります。
従来は弊社のようなデータウェアハウス環境を持たない企業では太刀打ちできない規模のデータでした。あえて分析するとすれば、データをいくつにも分割して、各々を処理するということをせざるを得ません。その分割処理によって処理自体は実行できます。しかしその作業には莫大な時間がかかります。我々が実施したい手軽に試行錯誤しながら分析するということは不可能でした。
それがRedshiftですと、数十億行のデータでもかなりのスピードで動きます。たとえば、60億行あるデータからとある条件で絞り込みを行い、300万行のレコードだけを抽出するという処理は3分程度で完了するという実績でした(RedshiftのXLノードを4 ノード立てた環境)。さすがにサクサク動くというわけではないですが、この程度の待ち時間ですと試行錯誤しようというモチベーションを極端に削がれません。
また特筆すべきは、そこにかかるコストです。弊社ではAWS上で、Redshiftのほかに、S3というクラウドストレージやEC2という仮想サーバーも使用していますが、その利用額は月額で10万円程度です。弊社のようなベンチャー企業にとっても十分に支払っていけるコスト感です。SaaS型のサービスですので1-2か月利用して、うまくいかなければ利用を止めるということも可能です。
Redshiftを使うためには、SQLというプログラミングがかけなければというスキル面の障壁はあります。しかしそれさえ乗り越えれば、数十億レコード規模のデータでも安価に高速に扱うことができる時代になっています。
ビッグデータ分析体系の連載のまとめ
本連載ではギックスのビッグデータ分析の体系についてその外観をご紹介しました。
お伝えしたかったのは、手軽にビッグデータを分析できる環境が整ってきているということ。また我々の分析体系に沿って分析いただければ、企画・マーケ部門の皆様が事業をよりよくしていくためのアウトプットを出せるということです。
ぜひ気軽にビッグデータ分析にトライしてみてください。思いのほか簡単にビックデータが分析できるようになっていることを実感いただけると思います。




