
目次
第2回は「文字化けあるある」です。
前回は文字コード関する基本的な知識をまとめてみました。第2回の今回は「じゃあ文字化けはどういった場合に起こるの?」という場面についてパターン分けして説明していきたいと思います。皆さんも心当たりがあったら「ああ、あるある!」っとツッコミを入れてください笑。
まず、文字化けの原因から
みなさんご存知の通り、文字化けとは「コンピュータ上で意図しない文字が出力されている状態」の事ですが、これをもうちょっと掘り下げると、
入力(ファイル)
↓(①)
プログラム
↓(②)
出力(画面やファイル)
上記の①もしくは②の文字コードの指定で「意図しない何かがあった」事が原因で引き起こされる悲しい状態である、という表現ができます。今からその「意図しない何か」を見ていきましょう。
Note:
前回も申し上げましたが本連載は文字化けの原因について「データの欠落・破壊」を除いて執筆させていただいています。
意図しない何か=単純に間違えた、というパターン
まずは一番単純なパターンです。上記①もしくは②を間違えた場合です。Windowsのメモ帳を例にとります。メモ帳からファイルを開こうとしたときに以下のような画面を目にしたことがあると思います。
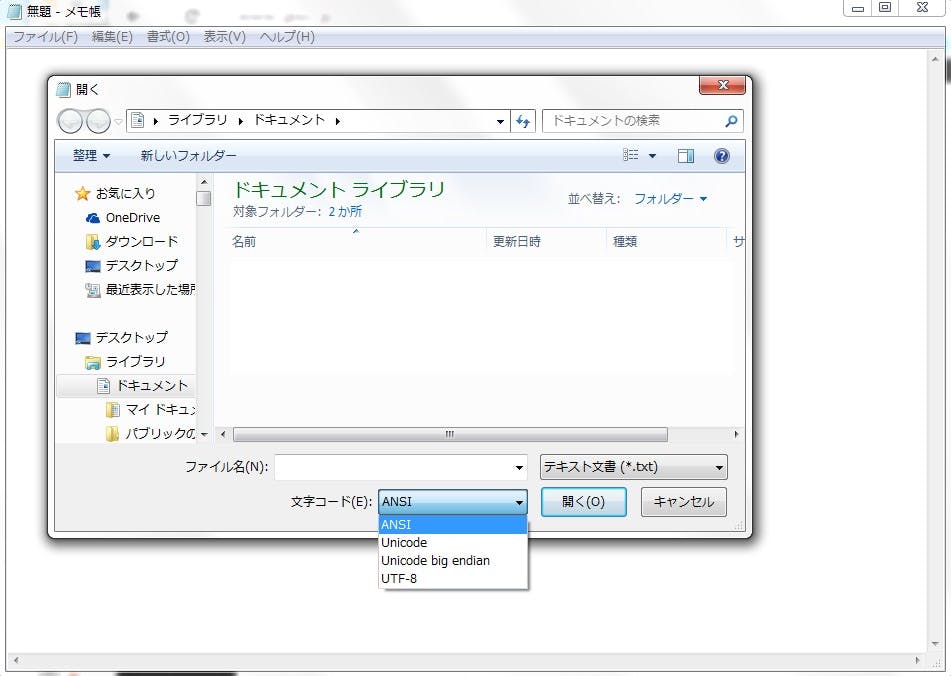
ここで真ん中下のほうにある「文字コード」の選択ボックス、この指定を間違えた状態が①の状態です。試しに皆さんのパソコンにあるファイルをいろいろな文字コードで開いてみてください。文字化け状態が味わえると思います笑。でも!絶対にその状態で保存しないでくださいね。ダメ!ゼッタイ!
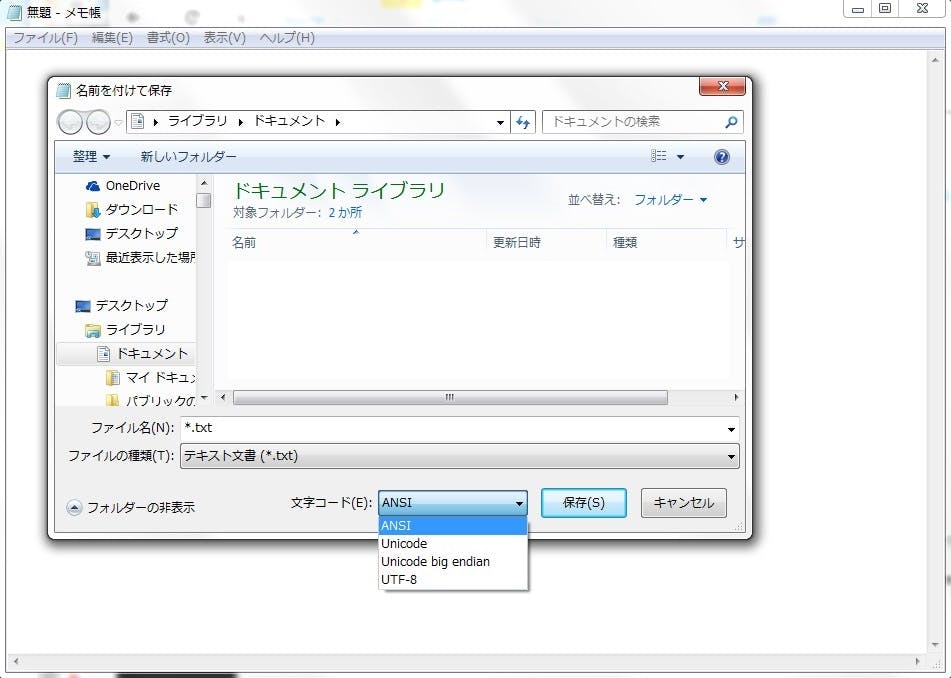
そして、②はファイルを開いた後に保存しようとする状態、すなわち下の画面の文字コード指定を間違えた状態なのです。でもメモ帳はここで文字化けを起こすことはありません。優秀なプログラムであるメモ帳にはここで間違いを起こさないような対策が幾重にも施されているからです。しかし欠陥のないプログラムなど存在しません。世の中の多くのプログラムがこの状態での振る舞いをうまくできないことによって文字化けという悲しい状況が起こっているのだということをお分かりいただけたらと思う次第です。(今私は完全にプログラマ心でこの記事を執筆しています泪)
意図しない何か=デフォルトが予想と違った、というパターン
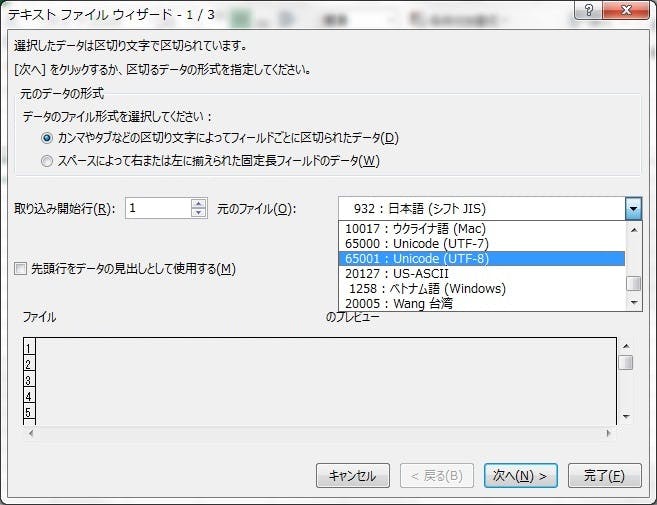
みなさん「デフォルト」という言葉になじみはありますでしょうか?デフォルトとは「初期値」という意味や「使用者が意図的に値を設定する前に、もともと製造者が設定した値」という意味があります。買ってきたばかりのエアコンのリモコンに電池を入れた時に25℃と表示されていたら、その25℃はデフォルトと言えます。このデフォルトの文字コードがプログラムにも用意されている場合があります。みなさんCSVファイルをダブルクリックしたときExcelが立ち上がって文字化けして表示されたことはありませんか?この状態がまさにこの場合かつ上記①の状態なのです。ほとんどの場合文字化けしたファイルはUTF-8の文字コードでデータを格納しているはずです。実はExcel日本語版がCSVファイルを読み込む際ののデフォルト文字コードはShift-JISと設定されているのです。そこにUTF-8で格納されたデータを読み込んだ結果、文字化けが起こったというわけです。ちなみにExcel中国語版のデフォルト文字コードはUTF-8です。Excel中国語版のインストールされたパソコンでShift-JISで記述されたCSVファイルをダブルクリックするとやはり文字化けが起こります。ちなみにそんな時はExcelのメニュー「ファイル」から「開く」を選択して対象のCSVファイルを指定してください。以下のような「テキストファイルウィザード」が表示されます。画面中段で文字コードを選択することができます。ここを正しい文字コード(多くはUTF-8)を選択して処理を続行してみてください。
私見ですが、おそらく世の中のプログラムで起きている文字化け原因のかなりの割合がこのパターンであると感じています。文字を扱うプログラムはこのデフォルト文字コードに対する振る舞いを設計に織り込む必要があるのですが、この部分の設計を失念した結果「デフォルト文字コード=OSの文字コードを使用する」という処理を行ってしまい①もしくは②に間違いが生じるという欠陥は非常に一般的です。
意図しない何か=表す文字がない、というパターン
これはとにかく以下の表をご覧になってください。
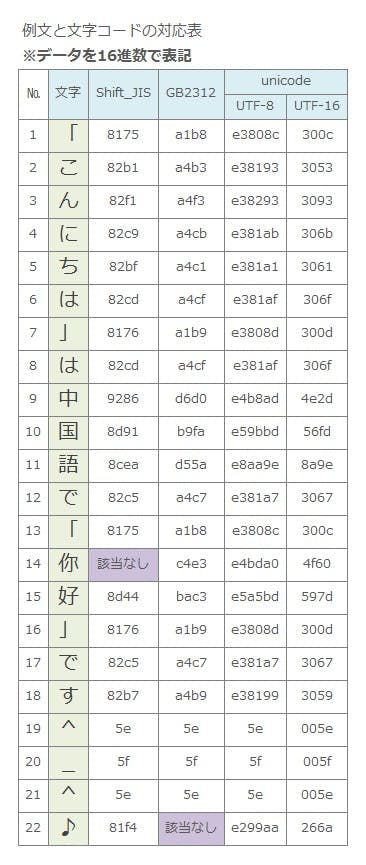
上記の薄紫のマスがこのパターンです。文字コードにはそもそも「表現できる文字の種類」に限りがあります。この話はまたの機会にするとしてShift-JISは7070文字、GB2312は7445文字、Unicodeは113,021文字(Unicode7.0.0)をそれぞれ収録しています。この種類のずれは残酷で薄紫は「その文字コードでは表現できない」状態なのです。上記の図を例にすると、データをShift-JISで保存した場合、№14の「你」が文字化けします。またGB2312で保存した場合、№22の「♪」が文字化けします。ちなみにこの残酷さを少しでも救おうと「全ての文字を表現できる文字コードを!」という取り組みから生まれたのがUnicodeでありUTF-8なのです。前回の連載でも取り上げましたが、このUnicodeに関する取り組みが世の中に存在するデータの再利用性や自由度に大きな貢献をしたことは間違いありません。
今回はここまでです。みなさんの思い当たるパターンはあったでしょうか。次回は「じゃあ、なぜ初めからUTF-8が登場しなかったのか?そもそもなぜ複数の文字コードが存在するのか?」このあたりを中心にお話できればと思います。
【連載記事:いまさら訊けないビッグデータ分析】
- 文字コードや文字化けを理解しよう(その1)
- 文字コードや文字化けを理解しよう(その2) (本編)
- 「データマート」と「キューブ」の違いとは?
- カラムナー、キューブ、インメモリ…ビックデータ分析におけるデータベースのまとめ






