Amazon Redshiftへのデータインポートを2つのコンポーネントだけで行う ~TOSからAWSを操作~|Talend Open Studio によるビッグデータ分析(第7回)
- TAG : AWS | ETLツール | talend | Tech & Science | データハンドリング
- POSTED : 2015.08.29 09:36
f t p h l
tRedshiftOutputBulkExecコンポーネントを使用すれば、Amazon Redshiftのインポート処理を一括で行える
Amazon Redshift(以下、Redshift)は、ビッグデータに特化したDBとして広く知られています。Redshiftは、通常のSQL命令で問合せできるため、非常に扱いやすいのですが、大量データを登録する場合は、特殊なRedshiftのインポート命令と複数の手続きを行う必要があるため、若干のハードルがありました。これらの手間を解消するコンポーネントが、Talendには標準で備わっていますので、ご紹介します。
通常のRedshiftへのデータインポートの手続き
通常、CSVなどのデータファイルからRedshiftへ、データインポートを行う場合、下記のような手続きを行う必要があります。
- データファイルの読み込み
- 上記の情報をRedshiftで取込める文字コードに変換したインポートファイルを作成
- インポートファイルをAmazon S3へアップロード
- インポート先のテーブルのデータ削除
- インポート命令を実行してAmazon S3のインポートファイルを取込む
また、5.のRedshiftのインポート命令は、非常に設定項目が多いため、Redshiftの導入時に躓きやすいトピックだと思います。
これらのインポート手続きのうち、これからご紹介するコンポーネントは、2~5の手続きを行ってくれます。
Redshiftインポートコンポーネント(tRedshiftOutputBulkExec)の使い方
コンポーネントを配置する
始めに前回の応用でインポート先のRedshiftの接続設定を行います。作成した接続情報を画面中央の作業エリアにドラック&ドロップを行い、tRedshiftOutputBulkExecコンポーネントを配置します。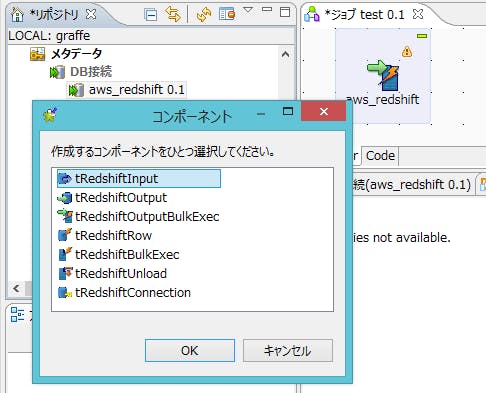
コンポーネントを設定する
tRedshiftOutputBulkExecコンポーネントには、多くの設定項目が存在しますが、基本的に下記の項目だけ設定すればインポート処理が行えます。
- Database setting – テーブル名:インポート先のテーブル名
- Action on table:「Clear table」を選択するとインポート前にテーブルのデータ削除を行う
- File Generate Setting:インポートファイルの出力先
- S3 Setting:インポートファイルのS3のアップロード先とS3への接続情報
あとは、入力ファイルの読み込みコンポーネントと紐づければジョブが完成します。(参考:Talendで簡単なジョブの作成) この時、入力ファイルのレイアウトとカラム名は、取込先のテーブルレイアウトと合わせる必要があります。
【参考】外部モジュールが見つからない場合
配置したコンポーネントを設定しようとすると、下記のような画面になっている事があります。これは、「コンポーネントを動作されるためには、外部モジュールの機能が必要なので設定してください」といった内容です。(tRedshiftOutputBulkExecの場合の外部モジュールとは、「AWS SDKのJavaライブラリ」の事です)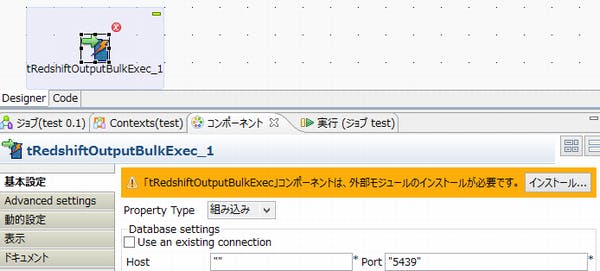
これは、Talendで必要な外部モジュールのダウンロードが完了していない事が原因です。そのため、画面の右下にダウンロード状況が完了すればコンポーネントが使えるようになります。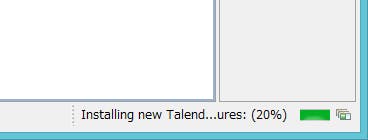
それでも状況が改善しない場合、なんらかの原因でダウンロードが中断している場合があります。再ダウンロードは、Talendのメニューバーの[ヘルプ]-[Install Additional Packages….]から行えます。(ここで表示したダイアログからプロキシ設定が行えます) また、何度か下記のような外部モジュールのライセンス認証を求められる画面が表示されますので、必ず同意を行ってください。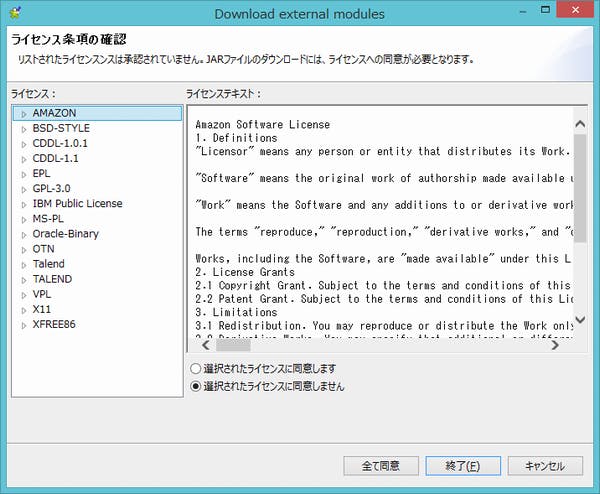
それでもダメな場合は、3つ前の画面の「インストール」ボタンをクリックして、そこで指定されているJARファイルをインターネット等で入手して、インストールしてください。私は、当時の最新のAWS SDK for Javaをダウンロードして、ZIPファイルの中のJARファイルをリネームして使ってました。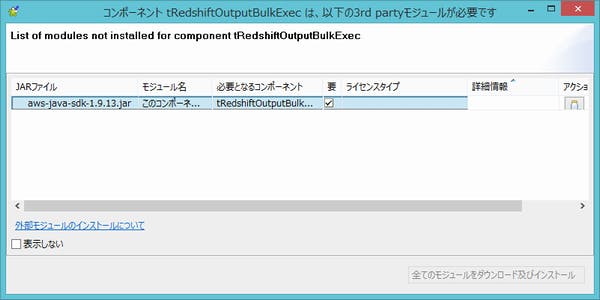
Talendの無償版の悲しいところですね~。たまにこんなこともあります。最新のTalendは直っていましたが、同様のケースが発生しましたら、ご参考にしてください。
TalendはAWSとの相性が非常に良い
今回は、可能な限りシンプルにするためにtRedshiftOutputBulkExecコンポーネントを使用して一括で処理しましたが、個別にAmazon S3(以下、S3)のアップロード(tS3Put)、Redshiftのインポート(tRedshiftOutputExec)などが行えます。これらの機能を含んだシステム構築には、プログラムスキルが必須となりますが、S3、Redshiftに関しては、基本的な操作はTalendのコンポーネント設定だけで行えます。これによって、AWSの技術的なハードルをグッと下げたことになります。
更に、tJavaコンポーネントとtLibraryLoadコンポーネントで外部ライブラリの機能を使えますので、直接、AWS SDKからAmazon Kinesis、Amazon SQSなどの多くのAWSサービスを操作することも可能です。そのため、AWSの操作をTalendのジョブだけで構築可能になっています。
【連載、Talend Open Studio によるビッグデータ分析】
- ”Talend”と”RapidMiner Studio”、2つのETLツールを比較してみた
- Talendのインストールと初期設定(Windows 8.1編) ~Javaのバージョンに気を付けろ~
- Talendで簡単なジョブの作成
- フォルダ中のファイルを変換して1つにまとめる
- フィルタリングと文字列置換とプログラムによる変換方法
- DB間のデータコピーを2つのコンポーネントだけで行う
- Amazon Redshiftへのデータインポートを2つのコンポーネントだけで行う (本稿)
- Talendがバッチ処理の開発方法を変える ~スマートな開発を行おう~
- Talendの無償版(TOS)と有償版(Enterprise)の違い
- TOSを使ってMicrosoft Azure SQL Data Warehouseを操作する
- TOSでギガ単位の適切なテストデータを作成する
- Web API からの取得結果をデータベースに登録する処理をノンプログラミングで実現する
f t p h l