データアレンジメントがビッグデータ時代の新潮流になる。|データクレンジングの限界を越えよう
- TAG : Tech & Science | データアレンジメント | ビッグデータ分析
- POSTED : 2015.11.04 08:24
f t p h l

データを深掘るならデータアレンジメントのスキルが必要!!
「ビッグデータ」という言葉が一般的に使われるようになった近年、今まで分析できなかったデータウェアハウス(DWH)上の1TBを超えるような大量データもクラウドデータベースなどによって、容易に分析できるようになりました。そして、分析対象は、今まで分析の中心だったリレーショナルデータベース上の表形式の構造化データから、XMLデータやJSONデータなどの非構造化データまでに幅が広がって来ています。
これらのデータを分析に最適な形に成型するのが「データクレンジング」という作業になりますが、この様な多種多様なデータを扱う場合も「データクレンジング」だけで十分なのでしょうか? 私は、従来の「データクレンジング」の考え方では、一般的な分析しか行えず、これらの貴重なデータを100%活かしきれていないと思います。これから記載する内容は、SIer時代の経験と現在の経験を比較して、「データアレンジメント」のあり方について記載したいと思います。
データクレンジングとは?
データクレンジングについて、IT用語辞典の内容を引用します。
データクレンジングとは、データベースに保存されているデータの中から、重複や誤記、表記の揺れなどを探し出し、削除や修正、正規化などを行い、データの品質を高めること。
具体的な手法はデータの種類により千差万別だが、一般的な例としては、全角文字と半角文字の違いや、空白文字や区切り記号の有無、人名の異体字の誤りや姓名の分割・併合、法人名の表記(株式会社と(株)の違いなど)、住所や電話番号の表記法などが対象となり、それぞれについて表記ルールを決めて修正・削除などを行なっていく。
【引用元】IT用語辞典:データクレンジング
一般的なデータクレンジングは、DBのテーブル内に登録されたデータ処理内容は「名寄せ」や「洗い替え」などを行うことだと定義されています。そのため、データクレンジング対象となるデータは、テーブル上のデータ、または、CSVファイルなどの表形式の構造化データに限られます。従って、XMLデータやJSONデータなどの非構造化データまでは対応しきれません。
データアレンジメントとは?
データアレンジメントは、私の作った造語です。「Data Arrangement」の言葉が示す通り、データを最適な場所に最適な形で配置することに重点を置いています。この「データ」というのは、構造化データだけではなく非構造化データも含みますので、XMLデータやJSONデータなども処理の対象として考えています。
データクレンジングとデータアレンジメントの作業の違い
データクレンジングとデータアレンジメントの作業の根本的な違いとして「データ構造を変えるか変えないか」があります。
データクレンジングは、先で記載したようにデータ構造を変えずに「名寄せ」や「洗い替え」などを行い、基本的なデータ構造は変えずにデータ項目を補完することを目的としています。しかし、データアレンジメントは、必要によりデータ構造を変えます。データアレンジメントは、分析対象となるデータの構造原理や特性を理解し、どのようなデータが登録されているかを見極めます。そして、データ項目単位に情報を分解し、それぞれのデータ項目の関係が崩れないようにデータ分析に最適なデータ形式に再構築します。そのため、対象となるデータ形式は、表形式だけでなく、JSONデータなどの非構造化データ、または、規則性があればテキストファイルでも対応できます。

データクレンジングとデータアレンジメントは「ゴールが違う」
システム開発において、データクレンジングと称して、ETL(Extract/Transform/Load)処理の「Transform:変換・加工」を開発することが多々あります。この場合、データの変換・加工処理の一環として、データ構成の変更を含む場合があります。これは、本来のデータクレンジングの定義からは外れますが、実務上仕方のないことだと思います。
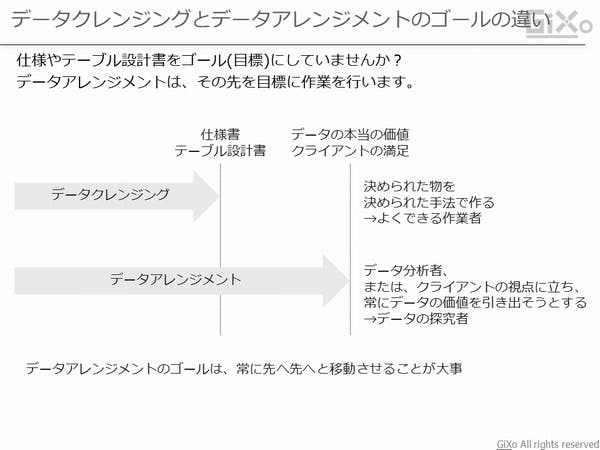
こう書くと、データクレンジングとデータアレンジメントの境界線は曖昧に見えてきますが、一つ、大きく異なる部分があります。それは、データクレンジングとデータアレンジメントでは、作業のゴール(目標)が異なるということです。
システム開発における”データクレンジング”では、クレンジングされたデータを「後工程ではシステムで利用する」という大前提があります。そのため、仕様書やテーブル設計書(項目設計書)などの明確な成果物が事前に定義されます。(逆にいえば、これが定義されていないと、クレンジング出来ません。)この目標に向けて、プロジェクトでスケジュールを決めて開発作業を行います。そして、仕様書やデーブル設計書の通りのデータを作り上げることがゴールになるのです。
一方、データアレンジメントのゴールは、データクレンジングよりも、業務の世界に踏み込んでいます。つまり、目指すものは「システム」ではなく、「クライアントの満足」なのです。世界中に散らばる多くの潜在的なクライアント企業は、例え業種業態が似ていたとしても、扱われているデータが全く同じということはありません。(SAPなどのパッケージソフトを導入していても、データ項目にはバラつきがあります。)そのため、データアレンジメントでは、クライアントとその保有するデータに合わせて、ゴールを変えていく必要があります。決して「仕様として決まっていないので、対応できません」とは言えないのです。
言い換えれば、データアレンジメントは、システム開発ではなく「コンサルティング」ひいては「顧客価値の創造」を目指しているのです。
データアレンジメントを行うということは、自律的且つ自発的に、目指すゴールを常に先へ先へと移動させる必要があります。なぜならば、クライアントや業務コンサルタントでさえもデータの本当の価値に気付いていないことが往々にしてあるからです。「こうすれば分析しやすいのではないか?」「このデータから(分析に有用な)こういう属性をつくりあげることができるのでは?」と常に考え、データを探求する必要があるのです。探求をあきらめたらそこでデータアレンジメントは試合終了です。
データアレンジメントを実現するためには、分析業務の実行体制が鍵
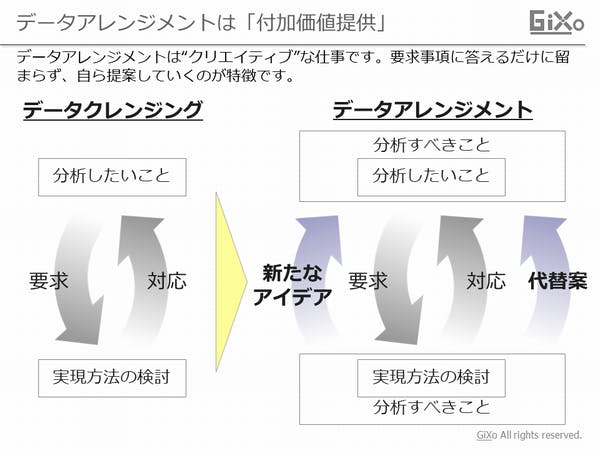
ここまで述べてきたように、データクレンジングは、与えられた仕様書やテーブル設計書の要求事項に向けて対応する”作業者的”な仕事です。対するデータアレンジメントは、要求事項に留まらず、新たなアイディアや代替案によって「分析すべきこと」を提案する”クリエイティブ”な仕事です。
データアレンジメントを活用していくための前提条件として、分析体制の構築が非常に重要になります。。
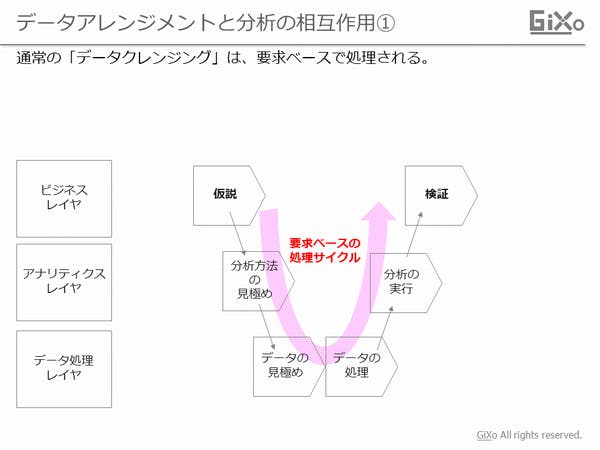
データ分析の業務レイヤを3層に分けてみます。弊社では、ビジネスレイヤ、アナリティクスレイヤ、データ処理レイヤの3層に分類しています。データ処理レイヤでデータクレンジング作業を行います。この時、インプットとなるのは、ビジネスレイヤから提示される「仮説」に基づいてアナリティクスレイヤで策定される「分析方法(あるいは分析方針)」です。データクレンジングは、この分析を実行出来るようにデータを成型します。その結果、準備されたデータを用いたアナリティクスにより、ビジネスレイヤで仮説が検証できれば”要求を満たした”ことになります。
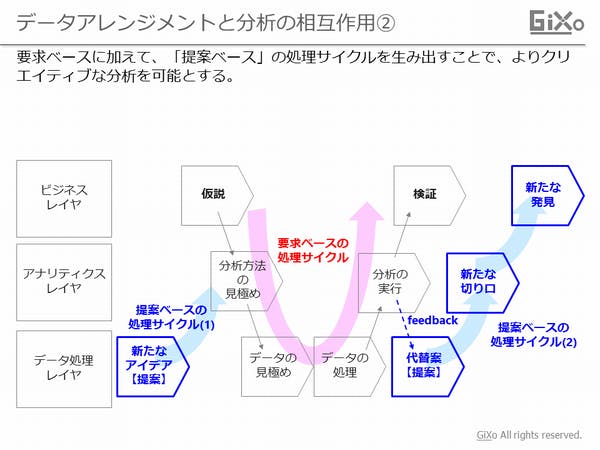
一方、データアレンジメントは、アナリティクスレイヤの「分析方法の見極め」に向けて、データの視点からアイデアを出します。これにより、アナリティクスレイヤとデータ処理レイヤが最適な共同でデータ構成を検討できるわけです。
更に、アナリティクスレイヤが分析した結果をデータ処理レイヤにフィードバックします。これにより、より分析に適したデータの保持方法をデータ処理レイヤから提案することができます。これは、アナリティクスレイヤにとって、新たな分析の切り口を見出すインプットとなります。このフィードバックは、最終的にビジネスレイヤが自分たちでは気付かなかった、ビジネス上の新たな発見へとつながっていきます。
ギックスにおいては、データ処理レイヤを私の所属する「Data-Structuring Section」で行い、アナリティクスレイヤを「Business Analytics Section」で行う、という機能分担になっています。それぞれの専門性を互いに理解しつつ、相互に刺激を与え続けることで、分析サイクルの短縮化と及び分析の高度化を実現しています。
データへの探究心こそが、データアレンジメントへの道!…かもしれない
データアレンジメントは、「データを基軸にして新たな発見をしたい」という欲求から生まれるケイパビリティだと私は考えています。言われた作業をただひたすらに行うだけに終始することなく、データを扱っている視点から活発に意見・アイデアを出し、新たな発見に結び付けていくことがとても重要です。そのためには、四六時中、データの構造を考え、脳内で様々なデータ構造のパターンを作って楽しむぐらいでないといけません。
ちなみに、私は、データをおかずに白飯を3杯食べれるくらいには、データが大好物です。我こそは負けず劣らずデータ中毒だ!という方は、弊社の扉を叩きにお越し頂ければ嬉しいです。ご応募お待ちしております。
f t p h l