
目次
ELT処理はクラウドデータベースだから可能になった荒業
皆さんは「ELT処理」をご存知でしょうか? 決して「Every Little Thing」ではありません。
ELT処理は、ETL(Extract/Transform/Load)処理の変換・加工(Transform)とデータロード(Load)の手順を入れ替えた「Extract/Load/Transform」から作られた新しいデータ分析用語です。一昔前まではETL処理がデータベースへのインポートの常識とされていましたが、近年のクラウドデータベースなどの進化によって、無作法とされてきたELT処理で行った方がスマートになるケースが増えてきました。今回はELT処理とその背景にあるクラウドデータベースなどのサービスについて説明したいと思います。
参考:[graffe.jp]ETLとは~あらゆるデータファイルを理解してデータベース化する~
ELT処理はデータベースを”道具”として使う発想から生まれた
以前、ブログでデータベースを”道具”として使うメリットについてご紹介しましたが、ELT処理はデータファイルをデータベースにインポートしてからSQL命令を使ってクレンジング作業を行う方法です。
ETL処理の変換・加工では、ETLツールやプログラミングによって処理を作ります。そのため、データ分析とは異なるスキルが必要になってしまいます。しかし、ELT処理の変換・加工では、データ分析でお馴染みのSQL命令で処理を行うため、新たなスキルはそれほど必要ありません。そのため、ELT処理の方がクレンジング処理を行いやす事があります。
全てのデータファイルがELT処理に対応できるわけではありませんが、データファイルがデータベースにインポートできるデータ構造であればELT処理を行うことができます。そして、データベースにインポートさえできれば、トリムなどの文字列編集、異常値の補正、コード名称変換などをSQL命令で行うことができるのです。また、コード名称変換などはSQL命令の方が通常プログラミング命令より処理のミスは少なく、処理速度も速い場合があります。
大容量のクラウドデータベースだからデータベース内で作業ができる
オンプレミスデータベースではデータベースに可能な限り負荷が掛からないようにインポート前にデータファイルを加工・変換することが主流とされていました。しかし、Amazon Redshift、Google BigQuery、Azure SQL Data Warehouse(以下、SQL DW)などのビックデータ用クラウドデータベースでは大容量、または無制限のストレージを比較的容易に準備することができます。そのため、データベースのストレージを気にすることがなくなり、クレンジング作業などのための中間テーブル(作業テーブル)を作りやすくなりました。
また、中間テーブル領域のために肥大したストレージは、その役目が終了次第、テーブル削除(truncate/drop)を行えばクラウドデータベースのストレージ課金を抑えることもできます。(Redshiftのストレージ容量を減らすためにはノードのリサイズが必要になります)
クラウドデータベースへのインポートも進化している
データベースに大量データを登録するためにはデータベースのインポート機能が必要になります。上記のRedshift、BigQuery、SQL DWにもそれぞれインポート機能があり、CSVデータのような構造化データだけではなく、JSONデータなどの非構造化データまで高速にインポート出来るようになっています。
しかし、インポート処理の場合、処理の最小単位がデータファイルになります。そのため、全ての対象データの取込が完了するまではデータベースのリソースを圧迫してしまいます。更にデータファイル中のデータフィルタリングが行えないため、不要なデータまで取り込むことになってしまいます。(オラクルのSQL Loaderなどのスクリプトローダーは除く)
これらの問題を解決するものがRedshift、BigQuery、SQL DWの外部参照テーブル機能です。外部参照テーブルは、データソースにデータインポートすることなく、クラウドストレージ上のデータファイルなどをテーブル感覚で直接参照することができます。これによって、インポート処理のために長時間リソースを圧迫されることなく、抽出条件(SQL命令Where)で必要なデータのみを効率的に参照・取込可能です。更に、Redshiftの外部参照テーブル機能の Redshift Spectrum は処理内部で分散処理を自動的に行っているため、非常に高速に大量データにアクセスできます。
この様にインポート処理や外部参照テーブル機能が進化したことにより、ある程度の大量・複雑なデータファイルでもインポート処理や外部参照テーブルだけで対応できるようになってきました。
ELT処理のポイント
弊社では2年以上前からELT処理による分析データの下準備を行ってきました。その中で得たETL処理のポイントについてご説明したいと思います。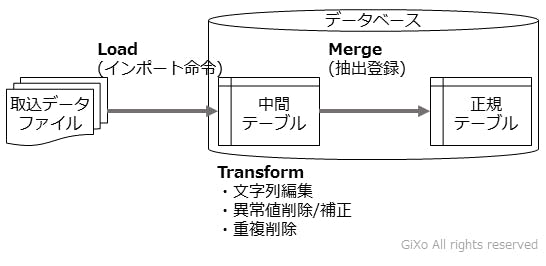
データロード(Load)
取込対象のデータファイルをデータベースのインポート命令でデータ取込します。この時、直接、正規テーブルにインポートせず、中間テーブルにインポートします。
中間テーブルに一度インポートする理由として、上記で説明をした変換・加工作業を行うためもありますが、正規テーブルにファイルデータを登録する前にデータ確認するためでもあります。データ確認を行わずに正規テーブルにインポートしていた場合、仮に不正なデータが混じっていると既存のデータが不整合を起こしてしまう場合があります。そして、インポート命令ではロールバック(インポート処理の取消)が行えない場合もあるため、中間テーブルを経由することをお勧めします。
また、中間テーブルのテーブル定義として、プライマリーキーなどの制約はなくし、文字列をデータ型の桁数は正規テーブルより多めに確保すると良いと思います。何故なら、ここで行うデータロード処理は、テーブルにデータを登録することが目的であり、漏れなくデータが登録できれば問題ありません。そのため、データファイルの内容がそのまま入るように中間テーブルの制約は緩くする必要があります。
変換・加工(Transform)
中間テーブルに対してSQL命令を実行して変換・加工を行います。
1回のSQL命令で全ての処理を完了させる必要はありません。複雑になる場合は、処理を複数回のSQL命令に分割して、変更結果を確認しながら進めていくとミスは少なくなると思います。また、中間テーブルも工程ごとに複数個作っていけば、もしミスに気付いて処理をやり直す時、途中の中間テーブルからリカバリーできますので後戻りは少なくて済みます。(中間テーブルが工程ごとに分かれていないとインポートからやり直すことになります)
マージ(Merge)
最後に中間テーブルから必要データをSQL命令で抽出し、正規テーブルにデータ登録します。
マージ処理で気を付けなくてはいけないことは、正規テーブルの整合性を保つことです。
例えば、定期的に差分データを抽出して、データ取込・分析を行うような定常業務があったとします。この定常業務の運用中の作業ミスにより、インポートデータファイルの中に過去分(正規テーブルに登録済み)が混じってしまったとします。この状態で正規テーブルにデータを登録してしまうとデータ不整合が起きるか、キー重複エラーでデータ登録が行えなくなってしまいます。
このような事態を回避するために、中間テーブルにデータが正しく正規テーブルに登録できるようにする必要があります。そのためには、テーブルのプライマリーキー項目などでデータの先入先出(正規テーブルのデータを中間テーブルのデータで上書き)、または後入先出(正規テーブルのデータを残し、中間テーブルから差分抽出)の制御をSQL命令を使って実現する必要があります。(先入先出はマスタ更新、後入先出はトランザクションデータ登録で使うことが多いです)
※「最後に”Merge”が在ったら、ELT処理ではなく、ELTM(Extract/Transform/Load/Merge)処理では?」というご指摘は無しでお願いします
今後、ELT処理の出番は多くなる
この様にクラウドサービスの進歩とともに、データベースの外で行っていた作業が、データベースの中でも行えるようになってきました。今後、完全にETL処理がELT処理に置き換わることはありませんが、徐々にデータベース外のデータの変換・加工処理がデータベース内の処理に比重が移っていくと思います。






