Python+Anaconda+Eclipseでロジスティック回帰プログラムを実行
前回の記事では、統計モデルを構築する上ために必要となるプログラム実行環境の構築手順を説明しました。今回は、実際にロジスティック回帰のプログラムを実行します。また次回でPythonとRでロジスティック回帰モデルの実行速度を比較するので、Rでのロジスティック回帰モデルの実行についても紹介しておきます。
Pythonのロジスティック回帰のプログラムのソース
今回の記事では、yhatさんのサイト(http://blog.yhathq.com/posts/logistic-regression-and-python.html)に掲載されているソースを参考にしました。今回実行するソースは以下のようになります。
| 01. | import datetime | // |
| 02. | import pandas as pd | // |
| 03. | import statsmodels.api as sm | // |
| 04. | import numpy as np | // |
| 05. | #----------------------------------------------------------- | // |
| 06. | timeStart = datetime.datetime.now() | // |
| 07. | print("timeStart:" + str(timeStart)) | // |
| 08. | #----------------------------------------------------------- | // |
| 09. | df = pd.read_csv("http://www.ats.ucla.edu/stat/data/binary.csv") | //データの読み込み |
| 10. | print (df.head()) | // |
| 11. | df.columns = ["admit", "gre", "gpa", "prestige"] | // |
| 12. | print (df.columns) | // |
| 13. | print (df.describe()) | // |
| 14. | print (df.std()) | // |
| 15. | data = df | // |
| 16. | data['intercept'] = 1.0 | // |
| 17. | train_cols = data.columns[1:] | // |
| 18. | logit = sm.Logit(data['admit'], data[train_cols]) | //ロジスティック回帰式実行 |
| 19. | result = logit.fit() | // |
| 20. | print (result.summary()) | // |
| 21. | print (result.conf_int()) | // |
| 22. | print (np.exp(result.params)) | // |
| 23. | params = result.params | // |
| 24. | conf = result.conf_int() | // |
| 25. | conf['OR'] = params | // |
| 26. | conf.columns = ['2.5%', '97.5%', 'OR'] | // |
| 27. | print (np.exp(conf)) | // |
| 28. | #----------------------------------------------------------- | // |
| 29. | timeFinish = datetime.datetime.now() | // |
| 30. | print("timeFinish:" + str(timeFinish)) | // |
| 31. | print("timeRunning:" + str((timeFinish - timeStart).microseconds) + "microseconds") | // |
| 32. | #----------------------------------------------------------- | // |
ソースの9行目に入力ファイルの設定が記載されています。このソースではインターネット上から直接ソースを取得するようにコーディングされていますが、もし実行時にパソコンがインターネットに接続していない状態であるならば、上記のファイルをあらかじめローカルにダウンロードしておいて、ローカルハードディスク上のファイルパス(“C:\~~~”)を9行目に記載してください。
Pythonの統計ライブラリーでの、ロジステイック回帰式の呼び出しは18行目に記述されていて、 statsmodels.api ライブラリのLogitという関数を使います
プログラムの実行
このコード部分(行番号を除く)をコピーして、Eclipse画面の右側ペインに貼り付けます。
ここで、コンパイルエラーは表示されないはずです。
では、実行してみましょう。前回と同様に、実行ボタン=画面上部のメニューバー下のに「緑色の三角マークのボタン(アイコン)」をクリックしてください。
プログラムが実行されると、画面の右側ペインの下半分に実行結果が表示されます。これでロジスティック回帰分析のプログラムが実行されました。
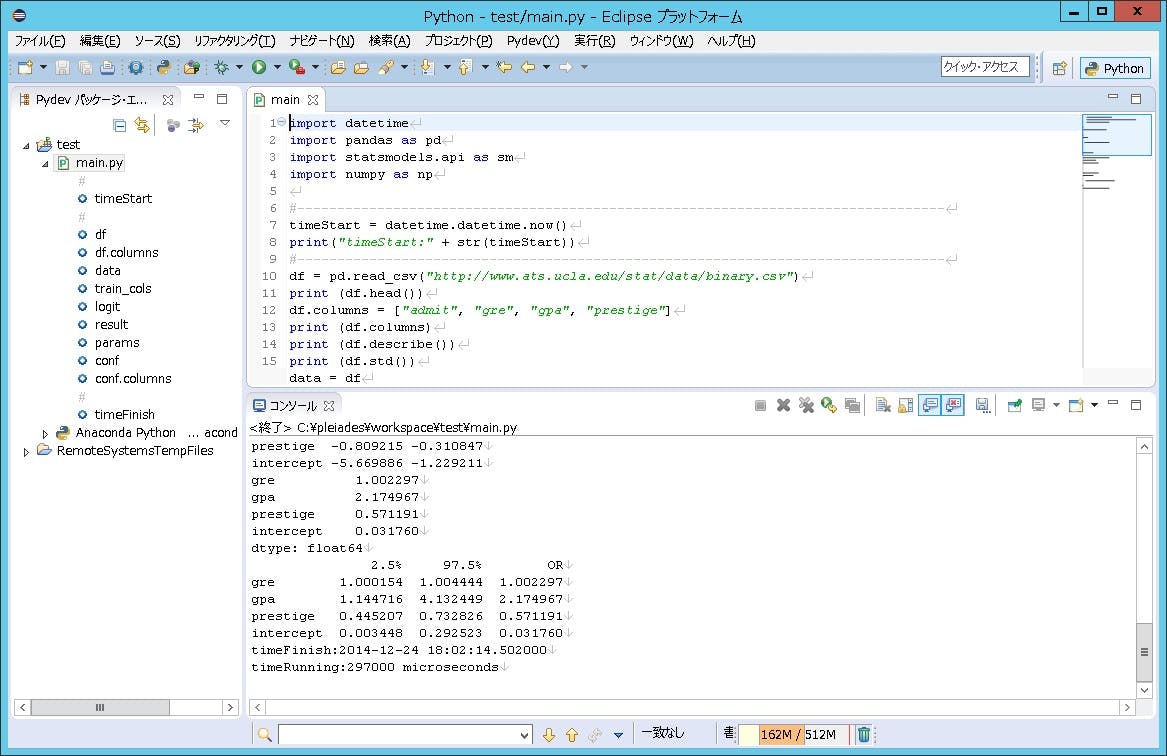
プログラムの実行結果は、以下のようになります。一番下の行に実行時間が表示されています。今回は約0.3秒で実行が終了しました。
| 01.| | timeStart:2014-12-24 18:02:14.205000 | ← |
| 02.| | admit gre gpa rank | ← |
| 03.| | 0 0 380 3.61 3 | ← |
| 04.| | 1 1 660 3.67 3 | ← |
| 05.| | 2 1 800 4.00 1 | ← |
| 06.| | 3 1 640 3.19 4 | ← |
| 07.| | 4 0 520 2.93 4 | ← |
| 08.| | Index(['admit', 'gre', 'gpa', 'prestige'], dtype='object') | ← |
| 09.| | admit gre gpa prestige | ← |
| 10.| | count 400.000000 400.000000 400.000000 400.00000 | ← |
| 11.| | mean 0.317500 587.700000 3.389900 2.48500 | ← |
| 12.| | std 0.466087 115.516536 0.380567 0.94446 | ← |
| 13.| | min 0.000000 220.000000 2.260000 1.00000 | ← |
| 14.| | 25% 0.000000 520.000000 3.130000 2.00000 | ← |
| 15.| | 50% 0.000000 580.000000 3.395000 2.00000 | ← |
| 16.| | 75% 1.000000 660.000000 3.670000 3.00000 | ← |
| 17.| | max 1.000000 800.000000 4.000000 4.00000 | ← |
| 18.| | admit 0.466087 | ← |
| 19.| | gre 115.516536 | ← |
| 20.| | gpa 0.380567 | ← |
| 21.| | prestige 0.944460 | ← |
| 22.| | dtype: float64 | ← |
| 23.| | Optimization terminated successfully. | ← |
| 24.| | Current function value: 0.574302 | ← |
| 25.| | Iterations 6 | ← |
| 26.| | Logit Regression Results | ← |
| 27.| | ====================================== | ← |
| 28.| | Dep. Variable: admit No. Observations: 400 | ← |
| 29.| | Model: Logit Df Residuals: 396 | ← |
| 30.| | Method: MLE Df Model: 3 | ← |
| 31.| | Date: Wed, 24 Dec 2014 Pseudo R-squ.: 0.08107 | ← |
| 32.| | Time: 18:02:14 Log-Likelihood: -229.72 | ← |
| 33.| | converged: True LL-Null: -249.99 | ← |
| 34.| | LLR p-value: 8.207e-09 | ← |
| 35.| | ====================================== | ← |
| 36.| | coef std err z P>|z| [95.0% Conf. Int.] | ← |
| 37.| | ------------------------------------------------------------------------------ | ← |
| 38.| | gre 0.0023 0.001 2.101 0.036 0.000 0.004 | ← |
| 39.| | gpa 0.7770 0.327 2.373 0.018 0.135 1.419 | ← |
| 40.| | prestige -0.5600 0.127 -4.405 0.000 -0.809 -0.311 | ← |
| 41.| | intercept -3.4495 1.133 -3.045 0.002 -5.670 -1.229 | ← |
| 42.| | ====================================== | ← |
| 43.| | 0 1 | ← |
| 44.| | gre 0.000154 0.004434 | ← |
| 45.| | gpa 0.135157 1.418870 | ← |
| 46.| | prestige -0.809215 -0.310847 | ← |
| 47.| | intercept -5.669886 -1.229211 | ← |
| 48.| | gre 1.002297 | ← |
| 49.| | gpa 2.174967 | ← |
| 50.| | prestige 0.571191 | ← |
| 51.| | intercept 0.031760 | ← |
| 52.| | dtype: float64 | ← |
| 53.| | 2.5% 97.5% OR | ← |
| 54.| | gre 1.000154 1.004444 1.002297 | ← |
| 55.| | gpa 1.144716 4.132449 2.174967 | ← |
| 56.| | prestige 0.445207 0.732826 0.571191 | ← |
| 57.| | intercept 0.003448 0.292523 0.031760 | ← |
| 58.| | timeFinish:2014-12-24 18:02:14.502000 | ← |
| 59.| | timeRunning:297000 microseconds | ← |
ロジスティック回帰の結果
ここで、このプログラムの処理が何を行っているかを簡単に説明したいと思います。まず、入力データは、「アメリカの大学院進学試験(GRE)を受験した人の合否データ」です。このデータは400件の行数を持ち、データ構造としては以下の列を持っています。
admit:大学院に合格した(=1) OR 不合格であった(=0)
gre:大学院進学のための試験(Graduate Record Examination)のスコア
gpa:大学の成績評価点平均値(Grade Point Average)
rank:大学のランク
今回は、このデータをロジスティック回帰の手法を用いて統計分析処理を行うということになります。
ロジスティック回帰の目的変数は、admit(大学院合格/不合格)で、説明変数は、gre(大学院進学のための試験のスコア)、gpa(大学の成績評価点平均値)、rank(大学のランク)の3つになります。
出力結果の38~41行目が分析結果になり、うち41行目は定数項になります。結果の解釈としては、3つの説明変数ともに5%水準で有意で、係数のオッズ比からみると、greの得点が100点高くなると合格率が約1.3倍に、gpaが1高くなると合格率が約2.2倍に、大学のランクが1ランク上がるごとの合格率が約1.8倍になると推計されます。
Rでのロジスティック回帰モデル
続いて回帰モデルをRでも実行してみます。Rの導入方法や使い方は、以前の記事をご覧になってください。今回実行するRのスクリプトコードは以下のようになります。
| 01. | t <- proc.time() | ← |
| 02. | ||
| 03. | data1 <- read.csv(“http://www.ats.ucla.edu/stat/data/binary.csv”) | ← |
| 04. | ||
| 05. | head(data1) | ← |
| 06. | ||
| 07. | nrow(data1) | ← |
| 08. | ||
| 09. | ncol(data1) | ← |
| 10. | ||
| 11. | res1 <- glm(admit~.,data=data1, family=binomial(link=”logit”)) | ←ロジスティック回帰式の実行 |
| 12. | ||
| 13. | summary(res1) | ← |
| 14. | ||
| 14. | proc.time()-t | ← |
以前にも紹介したとおり、Rではglm関数でロジスティック回帰式を実行することができます。(ちなみにglm関数は一般化線形モデルの関数で、引数にfamily=binomialに設定することでロジスティック回帰式と認識します)このスクリプトコードをR上で実行した結果は、以下のとおりです。
| 01.| | > t <- proc.time() | ← |
| 02.| | > | ← |
| 03.| | > data1 <- read.csv(“http://www.ats.ucla.edu/stat/data/binary.csv”) | ← |
| 04.| | > | ← |
| 05.| | > head(data1) | ← |
| 06.| | admit gre gpa rank | ← |
| 07.| | 1 0 380 3.61 3 | ← |
| 08.| | 2 1 660 3.67 3 | ← |
| 09.| | 3 1 800 4.00 1 | ← |
| 10.| | 4 1 640 3.19 4 | ← |
| 11.| | 5 0 520 2.93 4 | ← |
| 12.| | 6 1 760 3.00 2 | ← |
| 13.| | > | ← |
| 14.| | > nrow(data1) | ← |
| 15.| | [1] 400 | ← |
| 16.| | > | ← |
| 17.| | > ncol(data1) | ← |
| 18.| | [1] 4 | ← |
| 19.| | > | ← |
| 20.| | > res1 <- glm(admit~.,data=data1, family=binomial(link=”logit”)) | ← |
| 21.| | > | ← |
| 22.| | > summary(res1) | ← |
| 23.| | ← | |
| 24.| | Call: | ← |
| 25.| | glm(formula = admit ~ ., family = binomial(link = “logit”), data = data1) | ← |
| 26.| | ← | |
| 27.| | Deviance Residuals: | ← |
| 28.| | Min 1Q Median 3Q Max | ← |
| 29.| | -1.5802 -0.8848 -0.6382 1.1575 2.1732 | ← |
| 30.| | ← | |
| 31.| | Coefficients: | ← |
| 32.| | Estimate Std. Error z value Pr(>|z|) | ← |
| 33.| | (Intercept) -3.449548 1.132846 -3.045 0.00233 ** | ← |
| 34.| | gre 0.002294 0.001092 2.101 0.03564 * | ← |
| 35.| | gpa 0.777014 0.327484 2.373 0.01766 * | ← |
| 36.| | rank -0.560031 0.127137 -4.405 1.06e-05 *** | ← |
| 37.| | — | ← |
| 38.| | Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1 | ← |
| 39.| | ← | |
| 40.| | (Dispersion parameter for binomial family taken to be 1) | ← |
| 41.| | ← | |
| 42.| | Null deviance: 499.98 on 399 degrees of freedom | ← |
| 43.| | Residual deviance: 459.44 on 396 degrees of freedom | ← |
| 44.| | AIC: 467.44 | ← |
| 45.| | ← | |
| 46.| | Number of Fisher Scoring iterations: 4 | ← |
| 47.| | ← | |
| 48.| | > | ← |
| 49.| | > proc.time()-t | ← |
| 50.| | ユーザ システム 経過 | ← |
| 51.| | 0.08 0.07 0.39 | ← |
| 52.| | > | ← |
| 53.| | > | ← |
R実行結果の33~36行目とPython実行結果の38~41行目の値が同じであることから、両者の実行結果が等しいことがお分かりいただけると思います。
Rでもgml関数の一行でロジスティック回帰を実行できますが、Pythonも同様にlogit関数一行で実行できて、本当に便利になりました。数年前には考えられないことですよね。
次回は、いよいよRとPythonの実行速度の比較についての当社実装データを紹介します。
第1回 Python+Anaconda+Eclipseを導入
第2回 Python+Anaconda+Eclipseをインストール
第3回 PythonとRでロジスティック回帰の実装(今回)
第4回 PythonとRでロジスティック回帰の実行速度比較