フォーマット解説の第四弾(最後)はJSONフォーマットです
フォーマット解説の第四弾(最後)はJSONフォーマットです
前回(第5回)は、各フォーマットを説明していく第三弾としてXMLフォーマットについて説明しました。今回は第四弾としてJSONフォーマットについて説明します。JSONは第4回(フォーマット説明第二弾)で説明したCSVフォーマットと同様にRFCによって仕様が公開されておりRFC4627としてナンバリングされています。クレジットが2006年7月なのでまだ10才に満たない若いフォーマットと言えます。JSONは正式名をJavaScript Object Notation(直訳するとJavaScriptオブジェクトの表記法)といいますが、現在はJavaScriptに限らず多くのプログラムから利用されておりその範囲や用途は急速に拡大し続けています。その多くは既存のXMLフォーマットの用途を置き換える形で進んでいるのですが、実際私自身も過去にXMLで策定していたデータ交換仕様を同様の業務で現在はJSONで策定しています。これはすなわち「JSONも表現の自由度やデータ再利用性の高さに強みを持つフォーマットである」ということを表しているのですがそれだけではありません。XMLより後発でありながら急速に広がりを見せるJSON、その特徴を見ていきましょう。
これまでの記事と同様に、本連載で取り上げているフォーマットの一覧を再掲します。
- フラットフォーマット(固定長フォーマット)
- Character-Separated Valuesフォーマット(CSV,TSV,SSVなど)
- XMLフォーマット
- JSONフォーマット ←今回
また、これまで例題としてきたサンプルデータも再掲します。
| 順位 | 氏名 | 本数 |
| 1 | 王貞治 | 868 |
| 2 | 野村克也 | 657 |
| 3 | 門田博光 | 567 |
| 4 | 山本浩二 | 536 |
| 5 | 清原和博 | 525 |
※出展:日本プロ野球機構オフィシャルサイト・歴代最高記録 本塁打 【通算記録】より
JSONファイルはデータが囲われてand区切られている
連載第1回でも申し上げましたが、上記サンプルデータをJSONフォーマットで表すと以下のようになります。
| [ | ||||||
| { | ||||||
| “順位”:1 | , | “氏名”:”王貞治” | , | “本数”:868 | ||
| } | ||||||
| , | ||||||
| { | ||||||
| “順位”:2 | , | “氏名”:”野村克也” | , | “本数”:657 | ||
| } | ||||||
| , | ||||||
| { | ||||||
| “順位”:3 | , | “氏名”:”門田博光” | , | “本数”:567 | ||
| } | ||||||
| , | ||||||
| { | ||||||
| “順位”:4 | , | “氏名”:”山本浩二” | , | “本数”:536 | ||
| } | ||||||
| , | ||||||
| { | ||||||
| “順位”:5 | , | “氏名”:”清原和博” | , | “本数”:525 | ||
| } | ||||||
| ] |
「固定長フォーマットはデータがフラットに記述されている」「CSVフォーマットはデータがデリミタで区切られる」「XMLはデータがタグで囲まれる」ことに対して、JSONはデータが角かっこ”[]”や波かっこ”{}”タグで囲まれ、かつ各データがコロン”:”やカンマ文字で区切られています。またかっこの中に子供のかっこを記述することもできます。これによって全体が木構造(ツリー構造)であらわされます。なんだかXMLとCSVをいい感じで混ぜたようなフォーマットですね?実は今回はこの「いい感じ」という言葉をキーワードにして説明をしていきたいと思います。
ちょっと大脱線
ここでおなじみの脱線タイムです。今回は大脱線します。なぜかというとJSONの特徴を説明する上ではいくつかのプログラム的な考え方を知った上でないと実感がむずかしいしいからです。ちょっとだけプログラム話につきあってください。
配列について
JSONを理解するうえで大切なのが配列という考え方です。配列とはデータの表記法でデータのまとまりを「添え字」で管理する方法です。普通の配列は添え字を数字で表します。この添え字には文字列を指定することも可能で、このような配列を連想配列と呼びます。
| 普通の配列の例: |
| 1,王貞治,868 |
| ↑ |
| 「配列の0番目の値が1、1番目の値が王貞治、2番目の値が868」という配列です。 |
| プログラムでは配列の添え字は0からはじめるのが一般的です。 |
| . |
| 連想配列の例: |
| “順位”:1,”氏名”:”王貞治”,”本数”:868 |
| ↑ |
| 「配列の順位キーの値が1、氏名キーの値が王貞治、本数キーの値が868」という配列です。 |
JSONは配列を表現するのが得意
さて話をJSONに戻します。実はJSONは配列を表現するのが得意なフォーマットなのです。なぜ得意であるかは後で説明します。JSONは配列を以下のような記述法で表現します。
| 普通の配列のJSON表現方法: |
| [1,”王貞治”,868] |
| ↑ |
| 配列全体を角かっこ”[]”で囲み、各要素値をカンマで連結 |
| . |
| 連想配列のJSON表現方法: |
| {“順位”:1,”氏名”:”王貞治”,”本数”:868} |
| ↑ |
| 配列全体を波かっこ”{}”で囲み、一つの要素を「キー文字列:値」で記述し、各要素をカンマで連結 |
さらにJSONの特徴として、上記の要素の値には数字や文字列はもちろんのこと、「子供の配列」を格納することが可能なのです。このことによって、JSONはXMLと同様に木構造(ツリー構造)を持つことが可能になります。つまり上記に掲載したJSONサンプルデータは、
- 1位の王さん、2位の野村さん…5位の清原さんという人の一覧を要素数5個の「普通の配列」として格納し、
- 上記aに関する一要素の値として、選手一人に関する情報(順位・氏名・本数)を「連想配列」として格納し、
- 全体として木構造になっている
というデータフォーマットを持っているのです。
こんなJSONフォーマットについて前回と同様に「第2回で説明した6つの共通的な取り決め」に照らし合わせて特徴を掘り下げていきましょう。
① データ構造
これまでの説明で私は、
- 1人目のデータを格納しているのはどの場所か。2人目のデータを格納しているのはどの場所か。
- 1人分のデータの中で、順位を格納しているのはどの部分か。同様に氏名は。ホームラン数は?それぞれどの場所に格納されているか。
これらに関する取り決めを定めている(=持っている)のは誰でしょうか?入力データでしょうか?プログラムでしょうか?という質問をしました。
JSONの場合、この答えは「データ側で定められている」です。
サンプルデータでは、データの構造はJSONに記述されている要素と一致しています。実はここから先の説明は前回のXMLと同様です。JSONもデータの再利用性の高さを長所として持っています。
前々々回・前々回・前回と同様に、本サンプルデータのデータ仕様の例を以下に示します。
| データ仕様 | |
| データ名 | 歴代ホームラン数の順位 |
| 文字コード | UTF-8(JSON規約におけるデフォルト) |
| 項目№ | 項目名 |
| 要素のキーに従う | |
前回と同様、ずいぶんフラットフォーマットやCSVフォーマットと比べて記述量が少ないですね?ほとんど内容が無い状態です。これまで説明させていただいた通り、上記のデータ仕様もAさん→Bさん→Cさん→Dさんとデータが手渡されていく際に上記のデータ仕様も一緒に手渡されていくわけです。この内容がほとんど無いということは「面倒くさくない」という状態です。この点に関しても「JSONはXMLと同様に再利用性の高いデータフォーマットである」と言えるわけです。
② 項目の最大データサイズ
このルールを持っているのもデータです。各項目は「連想配列」で表現されており各要素はカンマで区切られているというルールなので、項目の長さをプログラムで決める必要がないのです。
この観点において、「JSONは自由度の高いデータフォーマットである」と言えるわけです。
③ レコードの最大データサイズ
この取り決めに関しても定めているのはデータになります。本サンプルは歴代1位の王さんから歴代5位清原さんまで掲載していますが、このデータに6位のかたが加わったとしても、プログラムの処理に変更はありません。「XMLは自由度の高いデータフォーマットである」…と言いかけて、ここも前回と以下同文で、JSONデータもXMLと同様に木構造を持っているので同様の欠点を持っています。「JSONはフォーマット的な自由度が高い。しかしビッグデータ処理には向かないフォーマットである。」といえるのです。
Note:
前回、「実はXMLであっても件数の多いデータ処理は可能。でもXMLの良さを活かしきれない。」という説明をしましたが、これはJSONにもあてはまります。JacksonやJson-simpleと呼ばれる処理手法を用いることによって、JSONデータを「巨大な一本の木として扱わない処理手法」を採って処理速度を上げる事ができます。
④ 文字コード
この取り決めを定めているのはデータです。でもアプローチはXMLとは異なります。JSONのフォーマット内には文字コードを記述・宣言している箇所はありません。ではどうしているか?実はJSONフォーマットはRFCの規約として文字コードを取り決めているのです。デフォルト文字コードはUTF-8です。詳しくはRFC4627をご覧いただきたいのですが、第三章・Encodingに「JSON text SHALL be encoded in Unicode. The default encoding is UTF-8.」という記述があります。UTF-8は「全世界で使われている文字を全て収録したい」という目的の元に作られた文字コードであるため、今日利用されているほとんどの文字を扱うことが可能です(残念ながら完全な網羅は難しい状態ですが)。JSONは「UTF-8で全ての文字をまかなえるなら、XMLの様に文字コードを動的に取り決める必要はないじゃないか。UTF-8をデフォルトとするルールを仕様化してしまおう。」と考えたわけです。たしかにこれなら、このデータがAさん→Bさん→Cさんと手渡されていっても、AさんBさんCさんのプログラムは文字コードを気にする必要がないですよね。「JSONは文字コードに関して、再利用性が高いデータフォーマットである」と言えるのです。
⑤ エスケープ文字
この取り決めもデータが定めています。JSONにおいて文字のエスケープ処理はさきほどのRFC4627で仕様が以下のように定められています。
- 文字「”」は「\”」と表現する
- 文字「\」は「\\」と表現する
- 文字「/」は「\/」と表現する
- バックスペース文字は「\b」と表現する
- 改ページ文字は「\f」と表現する
- キャリッジリターン文字(CR)は「\n」と表現する
- ラインフィード文字(LF)は「\r」と表現する
- タブ文字は「\t」と表現する
- 16進数で表現されたユニコード文字は「\uXXXX」と表現する
XMLと同様JSONのエスケープ規則もCSVと比べて少々複雑ですが、仕様が厳格に定められておりCSVのようなあいまいさ(方言)がないので、処理の過程で間違いが起こることもほとんどありません。「JSONはエスケープ処理に関して、再利用性が高いデータフォーマットである」と言えます。
⑥ 処理速度
前回と同様、ここまでベタ褒めしてきた感があったJSONフォーマットですが、やはりフラットフォーマットやCSVフォーマットと比べるとその構造の複雑さゆえに処理速度においてはフラットフォーマット・CSVフォーマットに劣ります。しかしXMLよりは高速であると言えます。これはXMLがデータの区切りを判定する要素(開始タグ・終了タグ)の名前を自由に決められるのに対して、JSONはデータの区切りは角かっこ”[]”・波かっこ”{}”・コロン”:”・ダブルクォーテーションの各1バイトで固定的に仕様化しているので構文解析処理を高速化できる事が理由です。
まとめ:JSONの「ちょうどいい感じ」っぷり
以上、各フォーマット説明の第四弾としてXMLフォーマットについて説明しました。ここで多少の私見をまじえて今回のまとめを述べます。今回のまとめは私の言いたいことを先に書きます。
JSONは、
- CSVは構造も単純で処理は高速なんだけど、項目順と項目名の対応をいちいち制御するのがめんどくさいな。文字コードも事前に取り決めなきゃいけないし。
- XMLはそこらへん柔軟なんだけど、記述がごちゃごちゃしててちょっと冗長じゃないかな?テキストエディタで開くと見づらいし。
この二つの相反するわがままな要求に対して
- じゃあここらへんがちょうどいい感じんじゃいかな?
という巷の感覚でその適用範囲を広げているフォーマットだと私は考えています。
ここまで今回の記事をお読みいただいてお気づきの方も多いと思うのですが、今回のJSONに関する説明はその特徴の多くがXMLと重なっています。「項目順と項目意味の対応付けが不要」「木構造の採用」という特徴は、XMLの長所や短所をJSONも同じように持っていることを意味します。ゆえに「JSONデータの再利用性や自由度の高さ」も、一つのデータファイルが単独で複数の人の手やプログラムを渡り歩く現在のシステムにもとってまさにうってつけといえるものであり、ネット社会への貢献度は計り知れないといえるでしょう。
じゃあ、XMLと比べて何がちょうどいい感じなのか?
ちょっとここで、JSONとXMLのそれぞれのサンプルデータを横に並べてみます。
| 【JSONのサンプルデータ】 | 【XMLのサンプルデータ】 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
←→ |
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
構造はよく似ているのですが、JSONのほうがすっきり簡潔に表されている事にお気づきいただけると思います。
見た目が簡潔であるということは、それだけでそれを扱う人の手間を省き間違いを減らすことができるのでメリットとなります。また上記⑥処理速度についても述べたとおり簡潔なデータ構造を持つJSONフォーマットのデータはCSVには劣るもののXMLよりは高速であり、この点でもちょうどいい感じであると言えます。
しかしJSONのちょうどいい感じはここからが真骨頂です。ここからプログラムの話になっていきますので興味のない方はここでブラウザを閉じていただいてもかまいません笑。
JSONは「テキストデータをダイレクトにプログラムの変数として取り込む。およびその逆」な事に対してちょうどいいのです。つまりJSONはプログラムにとってすごく扱いやすいデータフォーマットなのです。
JSONは正式名をJavaScript Object Notationといいます。直訳すると「JavaScriptオブジェクトの表記法」となるわけですが、ここではオブジェクト=変数と考えてください。実はJSONは「JavaScriptで扱う変数をテキストとして表記したい」という目的のために考え出されたフォーマットなのです。その良さが他のプログラミング言語にも受け入れられて、今日多くのプログラム言語において「プログラム内の変数⇔JSON」という「ちょうどいい感じ」が享受されているのです。
参考までに上記のJSONサンプルデータをプログラムに取り込むと、以下のような構造を持つ変数として格納されます。
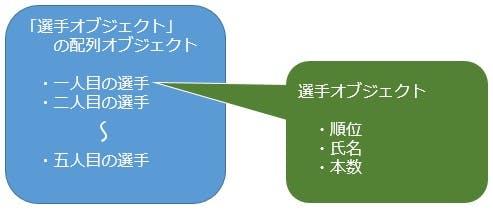
上記の「テキストデータをダイレクトにプログラムの変数として取り込む」という処理はJavaScriptであれば1行のコーディングで実現できます(evalという関数です)。この処理をフラットフォーマットで行おうとした場合、データを切って順番ごとに変数に格納しなければなりません。CSVではデータは分割されていますが、やはり項目順を制御しながら各変数に値を格納する処理が必要です。XMLではどうかというとXMLの構造が自由であるがゆえに「自由であるそのXML自身の構造をプログラムに宣言した後にプログラムの変数に格納する」というひと手間が必要になるのです。この「JSONは1行でOK!」というメリットは強力でデータ処理における大きなアドバンテージとして世の中に広がっています。まさにJSONは今の時代にちょうどいい感じだと私は考えています。
次回は総まとめです
次回、本連載の最後となる第7回は、これら4つのフォーマットの比較やその変遷についての総まとめを、これまた私の独断と偏見を交えて説明をさせていただきます。
あとがき
JSONとXMLとの違いをもう少し…
じゃあ「XMLとJSON、どっちがいいの?」という疑問があると思うので、ここであとがきとして書きます。答えは「どっちもどっち、使い方の用途による」です。ありていでごめんなさい。例えば、XMLのほうがデータを要素と属性の二種類で表現できるので、総じての表現力は上です。この点ではXMLの勝ちですが、だからといって「JSONで表現できることはXMLですべて表現できる」わけではないのです。その例をいくつか説明します。
例1:配列について
例えば「要素数が1つだけの配列」があったとします。例えば上記のサンプルデータで「データの中には1位の王さんのデータしかなかった」場合を想像してみてください。この場合XMLではこの要素が配列であるか否かを自身のデータ構造だけでは判定できないのです。対してJSONは角かっこ”[]”で囲うことでそれが普通の配列である事を明示しているのでデータ構造だけでの判定が可能です。この配列の表現においてはJSONの勝ちです。
例2:変数の型について
もう一つの違いが「データ型の情報をデータの中に持てるか?」です。XMLは表現力が豊かであるがゆえに値のデータ型をそのファイル自身では持っていません。デフォルトでは全て文字列型であると言えます(外部からの定義情報を参照することによって自由な型の表現を可能にしています)。対してJSONは数値、文字列、真偽値、配列といった型をJSONの仕様自身の中に包含しています。1ファイル単体としてのデータ型情報の取り扱いに関してはJSONの勝ちといえるでしょう。
これらの違いはXMLとJSONの生まれ持った構造の違いに起因するのですが、そのお話はまた別の機会とさせてください。
本連載について
- 第1回 いろいろなデータフォーマットが登場しています
- 第2回 データフォーマットを考える上での6つのポイント
- 第3回 フラットフォーマット(固定長フォーマット)について
- 第4回 Character-Separated Valuesフォーマット(CSV,TSV,SSVなど)について
- 第5回 XMLフォーマットについて
- 第6回 JSONフォーマットについて
- 第7回 まとめ