
こんにちは、ギックスのデータエンジニアの釣谷です。
2026年6月15日から18日まで、サンフランシスコのMoscone Centerで開かれたDatabricks Data + AI Summit(以下、DAIS)に現地参加してきました。3万人を超える参加者と、800を超えるセッション。会場の周辺はDatabricks一色で、グローバルでの勢いを肌で感じる数日間でした。

この記事は、DAIS 2026で何が発表されたのかを整理する紹介記事です。発表の内容は大きく分けて2種類で、1つ目がデータ基盤としての機能拡張、2つ目がAIエージェントプラットフォームとしての機能拡張です。
記事についても、2本に分けて書きます。今回の前半はデータ基盤まわりの発表を、後半はAI・エージェントまわりの発表を扱います。まずは「何が出たのか」を簡潔にまとめたいと思います。
前提を一つだけ。Databricksは「データレイクハウス」を中心にしたデータとAIのプラットフォームです。レイクハウスは、安く大量に貯められるデータレイクと、集計や分析が速いデータウェアハウスを、1つにまとめてしまおうという考え方です。今回の発表は、このレイクハウスの土台をさらに広げる方向に集まっていました。
データの取り込みと整備(Lakeflow)
最初はLakeflowです。データの取り込み(ingestion)、変換(transformation)、オーケストレーション(処理の流れの制御)を1つに束ねる、データエンジニアリングの基盤です。今回は、いくつかの構成要素が並んで発表されました。
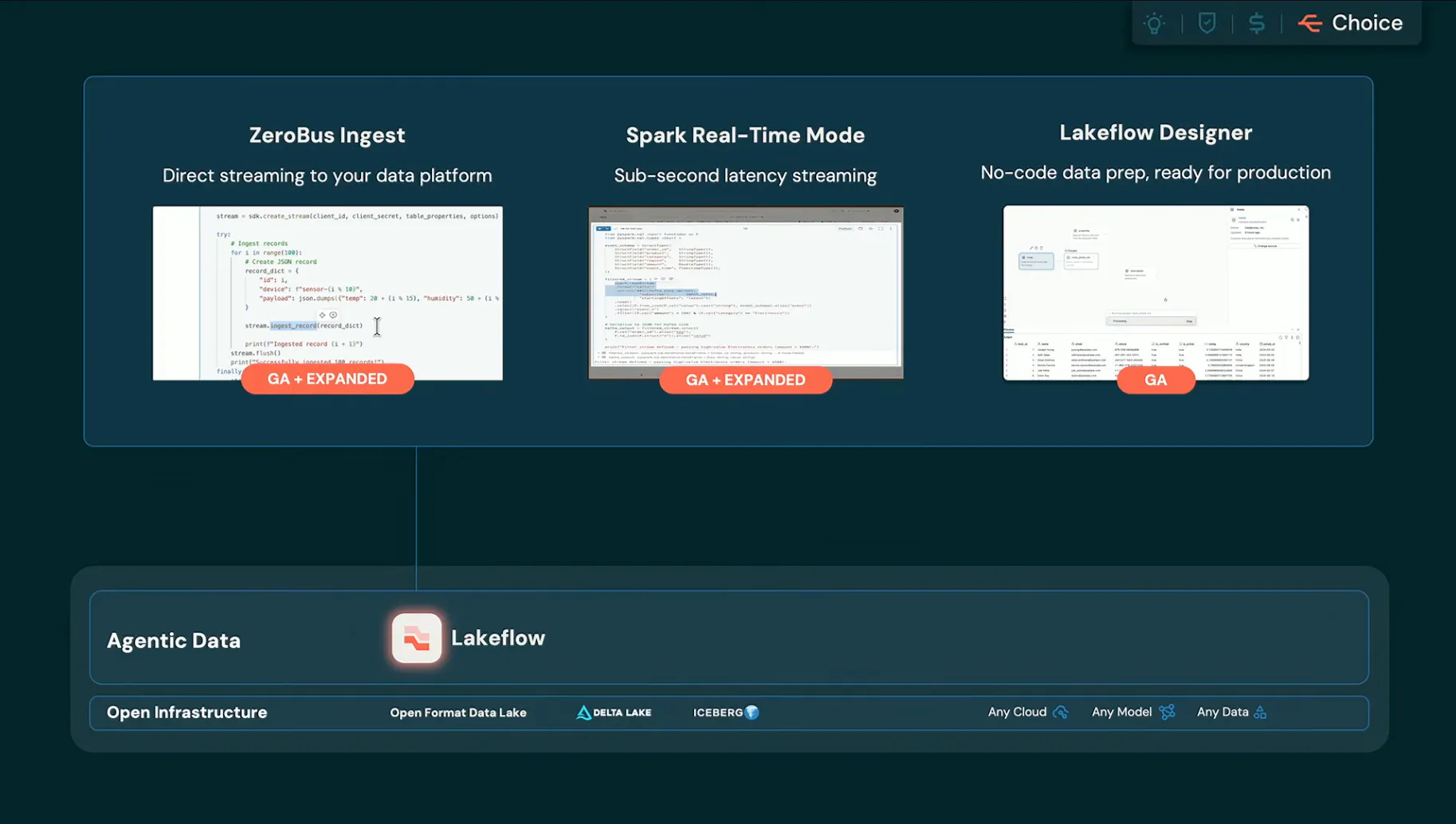
- Lakeflow Connect:業務アプリ、データベース、ファイルなどのデータソースからDatabricksにデータを取り込むためのマネージドコネクタ群。今回の大きなポイントは、コネクタの種類が大きく拡充されたことです。SaaS、データベース、ファイルソース、非構造化データまで含む100以上のコネクタで、取り込み処理をUnity CatalogのガバナンスやLakeflowのワークフローに載せやすくする発表でした。
- Lakeflow Designer:Databricks上でデータの結合、整形、検証をノーコードで行うための画面。今回GAとなり、作った変換を本番用のLakeflow Jobsに載せられる位置づけになりました。
- Zerobus Ingest:アプリイベントやセンサーデータのようなストリーミングデータを、Databricksに直接送るための取り込みAPI。別の取り込み基盤を増やさず、レイクハウスにほぼリアルタイムで流し込むための機能です。GA(Kafka互換APIはBeta)
- Spark宣言的パイプラインのリアルタイムモード:バッチとストリーミングのETLを宣言的に定義するSpark Declarative Pipelinesに、低遅延で動かすモードが追加されました。リアルタイム用途でも同じパイプライン記述を使えるようにする機能で、Public Previewです。
発表では、後半で触れるGenie Codeが、このLakeflowを使って取り込みから変換、オーケストレーションまでのパイプライン構築を自動化する、という連携も語られていました。
レイクハウス上のリアルタイム分析(Lakehouse//RT)
次がLakehouse//RTです。「RT」はリアルタイムの意味で、ダッシュボード、業務アプリ、可観測性のような「多くのユーザーやアプリが高速に読む」用途向けのリアルタイムデータウェアハウスです。
ここで大きかったのは、これまでDatabricks SQL Warehouseが担ってきた高速な分析実行を、レイクハウス上のデータへより直接つなげていく方向が示されたことです。従来のデータレイクハウスでは、分析基盤としては強くても、レイテンシの面では「1秒の壁」がありました。
Lakehouse//RTは、Reydenという新しいエンジンを基盤に、別の配信レイヤーへデータをコピーせず、レイクハウス上のデータにミリ秒級で問い合わせられるようにするものです。データレイクハウスの弱点だった1秒の壁を破りにいく発表だった、と理解しています。
発表された性能はデモを交えて具体的に発表されました。
- 標準的な分析ベンチマークで、1秒あたり12,000クエリをさばきながら100ミリ秒を切るレイテンシ
- 小さいデータセットなら最短10ミリ秒
- 既存のリアルタイム配信基盤と比べて最大16倍の性能
- 事例:Ciscoが応答時間の5倍改善、Magniteが主要ダッシュボードでサブ200ミリ秒
提供状況はBetaです。数千人から数万人がダッシュボードからクエリを投げるような規模だと、分析の速さは地味に効いてきます。また、AIエージェントにクエリを発行させてその結果を持ってLLMが深掘り分析するようなエージェントシステムのニーズが高まっているため、同時に大量のクエリを捌くLakehouse//RTの発表はAIエージェント時代への解決策として直球で来た発表だと感じました。
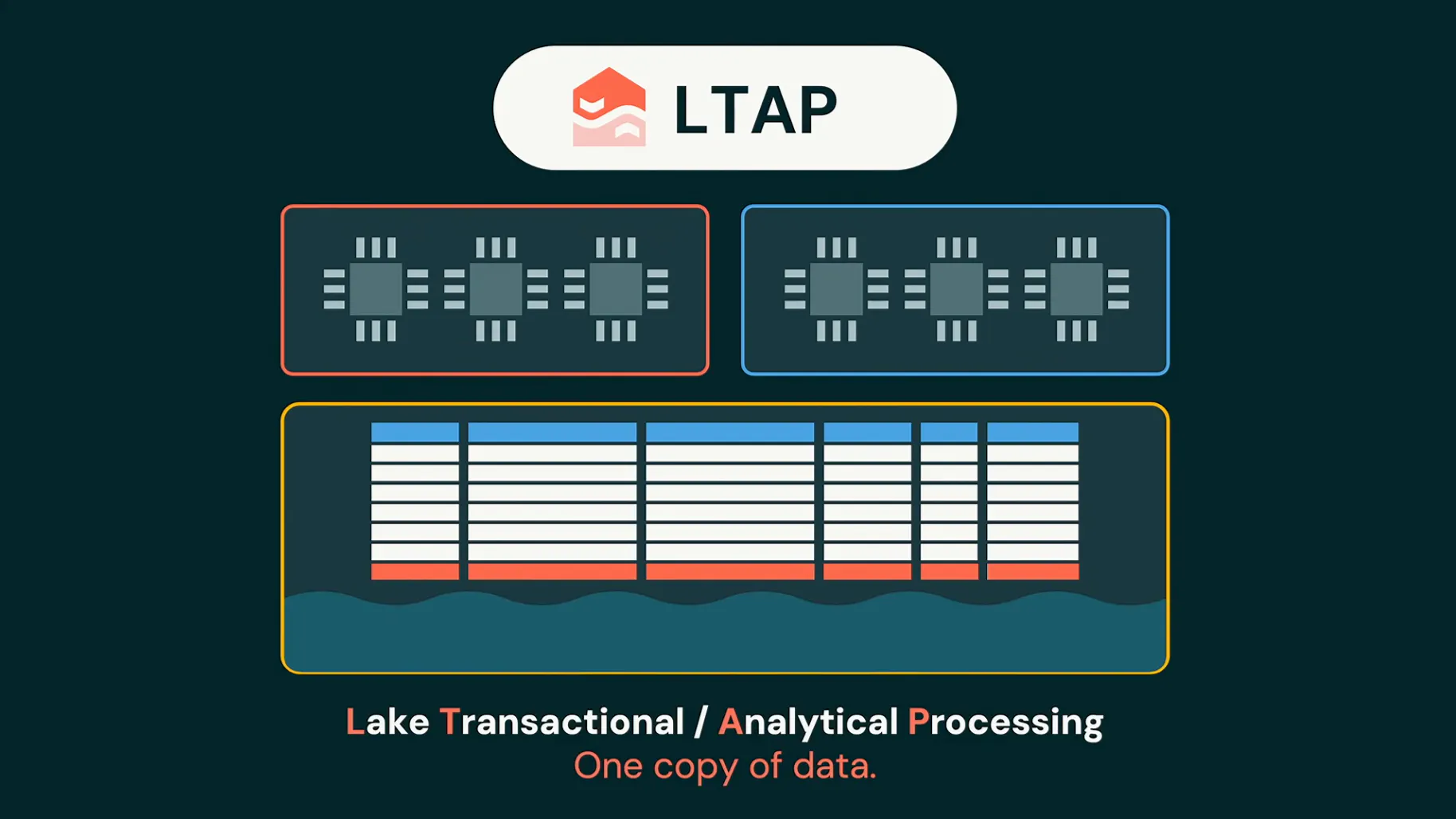
トランザクションと分析を1つにする(LakebaseとLTAP)
ここが今回のデータ基盤の発表で、いちばん構造的な話でした。
業務システムが日々データを書き込むトランザクション処理(OLTP)と、溜まったデータを集計する分析処理(OLAP)は、性質が違うので、これまでは別々のシステムに分けるのが普通でした。書き込み用のデータベースに溜めて、そこから転送して、分析側で集計する。この転送のぶん、データの鮮度は落ちるし、パイプラインの運用もコストもかかります。
その書き込み側を担うのがLakebaseです。アプリやAIエージェントが日々書き込むトランザクションデータを扱うための、Databricks上のサーバーレスPostgres Databaseです。今回の発表では、アプリ開発やAIエージェントの実行に必要なデータベースを、レイクハウスの近くで運用できるようにする点が強調されていました。
主な特徴は次のとおりです。
- 計算とストレージを分離し、必要なときだけ計算資源が伸び縮みする。使っていないときは計算資源を落とせるので、開発環境や一時的なエージェント実行にも向いている
- 本番データをコピーせずに開発・検証用の環境を分岐できるブランチと、スナップショットからの復元に対応する
- プラットフォーム全体で1日あたり1,200万回のデータベース起動を処理しており、短時間で大量のデータベースを立ち上げる用途を想定している
- リージョンやクラウドをまたいでワンステップで切り替えられる Multi-Cloud DR(災害復旧)により、障害時の復旧先を選びやすくする
提供状況は、Lakebase本体がGA、Multi-Cloud DRはこれから提供される予定です。
そして、このLakebaseと分析側をつなぐ考え方がLTAP(Lake Transactional/Analytical Processing)です。書き込みと分析を、別々のシステムではなく、オープンなデータレイク上の単一のガバナンスされた記録(system of record)として扱う。Lakebaseが書き込みを、Lakehouseが分析を担い、性能の妥協なしに1つにする、という打ち出しでした。
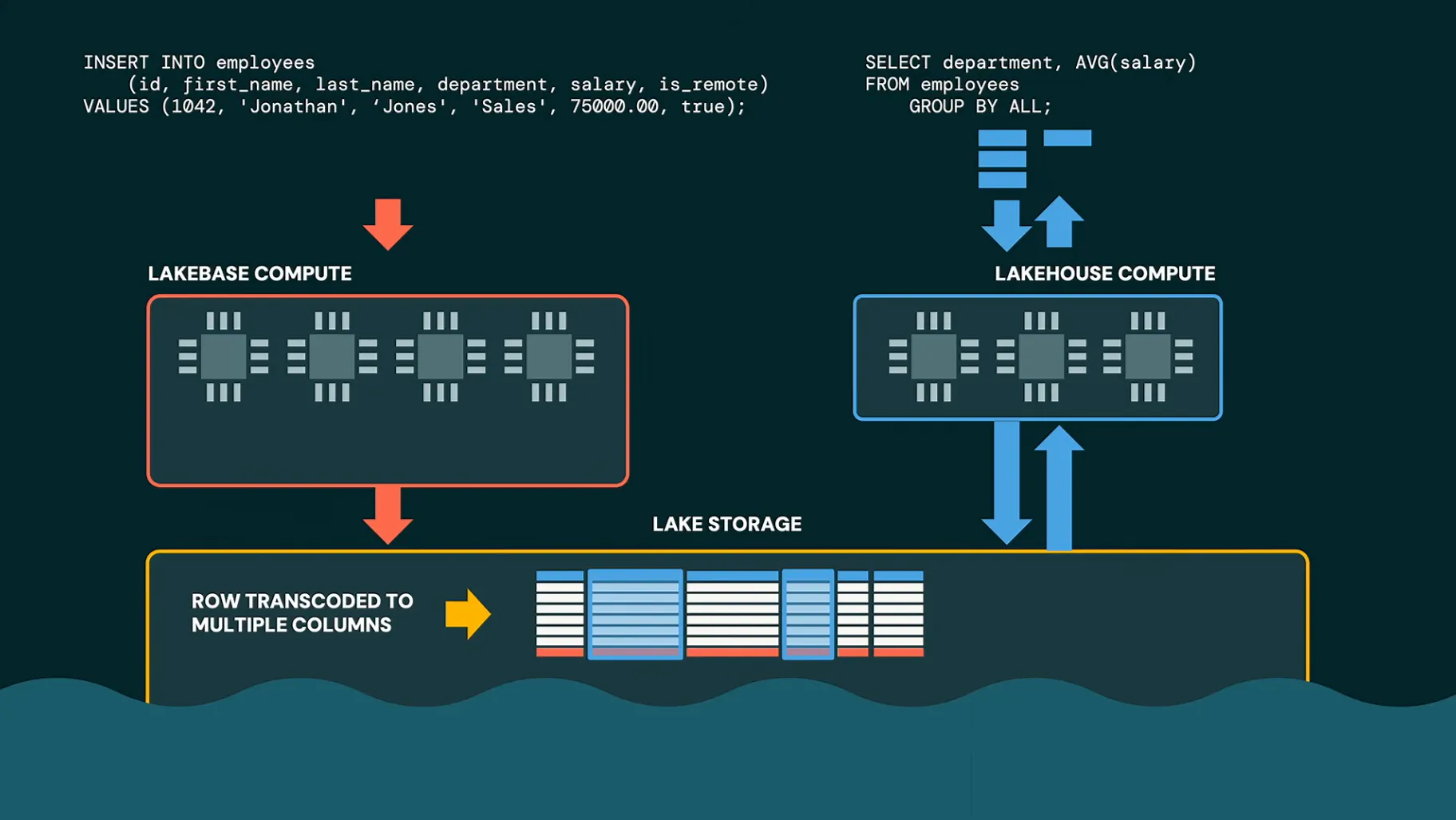
画期的だと感じたのは、Lakebaseに投入した行指向のトランザクションデータが、内部的に列指向へ変換され、Lakehouse側から読めるようになるという点です。これにより、これまで必要だったCDCやデータ転送、分析用コピーのためのETLパイプラインを不要にしていく、という説明でした。
列指向にすると圧縮も効いて、10対1から100対1ほどになります。つまり、業務アプリの最新データを、転送待ちの分析データではなく、そのまま分析やAIの入力に近づけていく発表です。近日中には、Lakehouseのリソース一覧にもLakebaseのリソースが表示されるようになるとのことでした。LTAPはComing soon(近日提供)の段階です。
ガバナンスの統一(Unity Catalog)
データが増え、使い道がAIにまで広がると、誰が何にアクセスできるかを束ねて管理する仕組みが要ります。それを担うのがUnity Catalogです。
今回のアップデートを提供状況ごとに整理すると、以下の通りです。
- Apache Iceberg v3 対応(GA):Icebergテーブルでも削除ベクトル、行トラッキング、VARIANT型などを扱えるようになりました。Deltaだけでなく Icebergも、Unity Catalogの管理対象として使いやすくする発表です。
- Databricks管理Iceberg、外部Iceberg、地理空間型(GA):Databricksが管理するIcebergテーブルだけでなく、外部にあるIceberg資産や位置情報データも、同じカタログと権限管理で扱う方向が強まりました。
- Databricks管理Deltaテーブルへの外部からの書き込み(Public Preview):Databricks外のエンジンから、Unity Catalogで管理されたDeltaテーブルへ書き込めるようにする機能です。読み取りだけでなく書き込みまで、外部エンジンとの相互運用を広げる発表です。
- FILE型(Beta):PDF、画像、Office文書のような非構造化ファイルを、テーブルのデータ型として扱う機能です。AIやRAGで使うファイルも、権限やリネージをUnity Catalogの枠組みで管理する狙いです。
一点、注意があります。Open Table Formatとして注目を集めるDelta LakeとIcebergですが、「どちらのフォーマットを選択するべきなのか」は長らく議論になっていました。そんな中、今回Icebergのv4とDelta Lakeとの完全な統合はロードマップとして語られました。v3では対応せず、具体的な日程ではないものの、1年以内にはv4のリリースが期待できる、という温度感でした。そのため、Delta Lakeを選んでも、Icebergを選んでも将来的には統合されるという点はOTFでの基盤開発を進めている開発者にとっての朗報でした。
また、Unity Catalogは、後半の記事で触れるUnity AI Gatewayを取り込み、アカウントやリージョン、クラウドをまたいで企業全体のデータとそのガバナンスを1つのビューで見られる方向に拡張されました。データのガバナンスとAIのガバナンスが、同じ枠組みに乗ってきている、という流れです。
データを閉じ込めない共有(OpenSharing)
最後がOpenSharingです。組織やクラウド、利用するエンジンが違っても、データやAIアセットをコピーせず共有するための、ベンダーニュートラルなオープンプロトコルです。従来の構造化データ共有を、AIモデルやエージェントのスキル、非構造化データまで広げる発表です。特徴は次のとおりです。
- Linux Foundationがホストするオープンソースプロジェクトで、特定のベンダーに縛られずに共有の仕組みを使える
- Apache IcebergのREST Catalogに対応し、共有先の環境にデータをコピーせず、元の場所にあるデータを参照できる
- 共有の対象は構造化データだけでなく、エージェントのスキル、AIモデル、非構造化データにも広がる
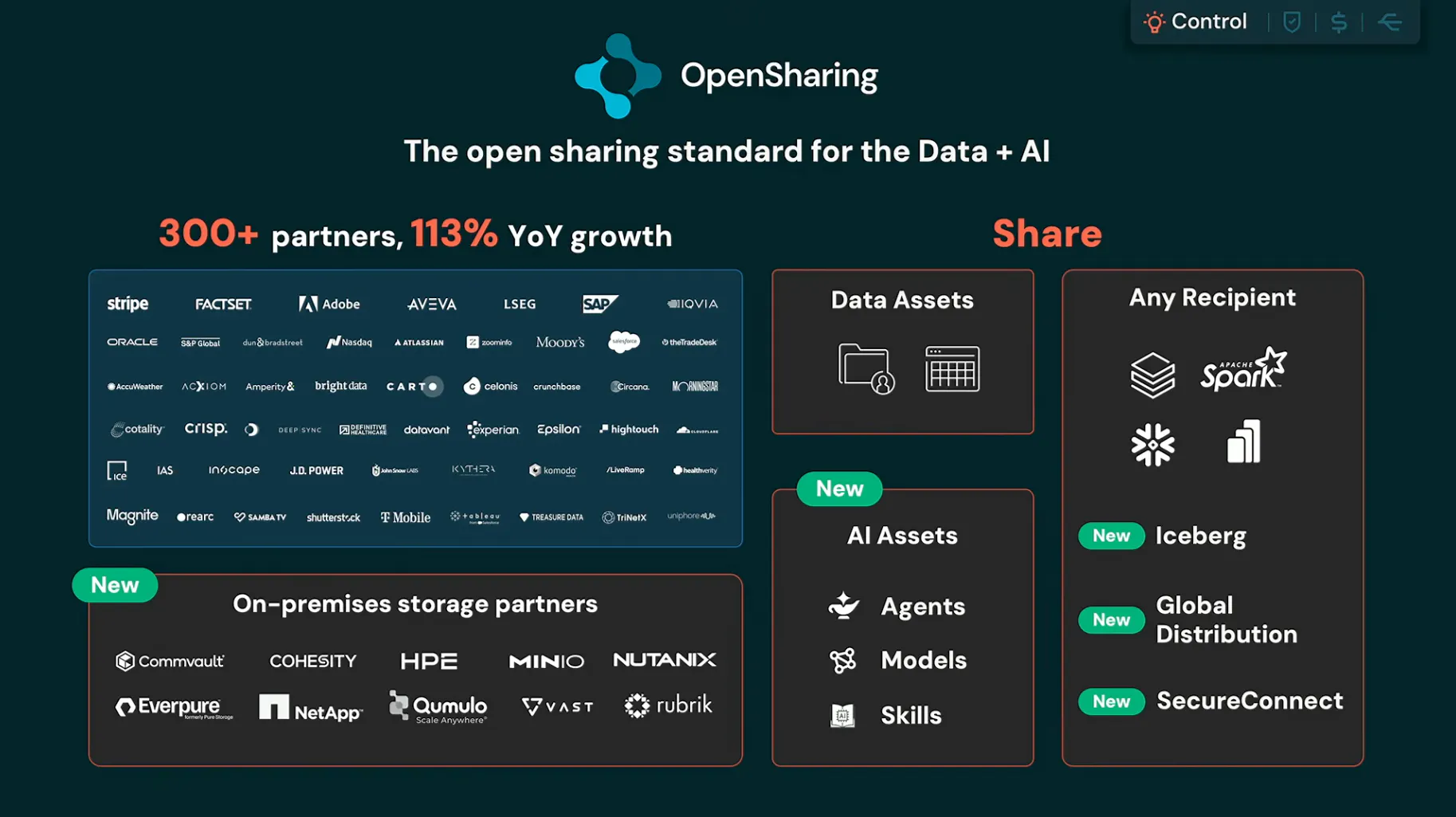
すでにGAで、GitHubで公開済みです。データがオープンな形式で、別の場所からも使える状態に保たれているほど、特定のシステムに縛られにくくなるため、移行のしやすさにもつながる発表でした。
まとめ
データ基盤まわりの発表を並べてみると、方向性は一貫していました。
データをできるだけ動かさない。
コピーや転送を減らす。
そして、オープンな形式で外からも使える状態に保つ。
Lakehouse//RTもLTAPもOpenSharingも、データ基盤を統合するための一貫した流れに沿った発表でした。
ここで紹介した多くは、まだPreviewやBeta、Coming soonの段階です。実際にどこまで使えるかは、これから触って確かめていきたいと思っています。
後半の記事では、このデータ基盤の上で動くAI・エージェントまわりの発表をまとめます。Genie やAgent Bricks、Unity AI Gatewayなど、「データから先、どう動くか」の話です。あわせて読んでもらえればうれしいです。








