
目次
200万件データのロジスティック回帰モデルでPythonはRより4倍早かった
前回の記事では、Pythonからロジスティック回帰のプログラムを実行しました。最終回である今回は、PythonとRで同じデータを使って同じ統計モデルを実行し、処理速度の比較結果を紹介していきます。
200万件データのロジスティック回帰モデルでPythonはRより4倍早かった
処理速度について、まず前回に紹介した「アメリカの大学院進学試験(GRE)を受験した人の合否データ」でRとPythonのロジスティック回帰モデルの処理速度を比較すると、R:0.39秒 Python:0.29秒とPythonのほうが30%ほど早い程度でした。このデータは400件と非常に小さなデータであるためにわずかな差にとどまったに過ぎません。
当社では別途約200万件の業務データを入力データとしPythonとRのロジスティック回帰式の実行比較を実施しました。結果、約4倍Pythonが早いという実測を得ました。また、マシンに搭載されているCPUの論理コア数が多ければ多いほどPythonの速度向上が認められ、PythonとRの速度差が大きくなるという結果を得ています。
なぜPythonのほうが早いのか?
では、なぜPythonでロジスティック回帰モデルを実行したほうがRに比べて処理速度が早いのでしょうか?
この速度差の理由の一つには、CPUの利用方法の違いが挙げられます。標準的なRの実行環境が処理をシングルコアで行うのに対し、Pythonはマルチコアで処理を行っていることが挙げられます。この事を確認すべく、両者が同一のデータを処理している場合のCPU負荷を参照してみました。
以下の図1のようにRはCPU0だけが負荷が高く、CPU1はあまり使われていません。おそらくCPU1はRの演算には利用されておらず、CPU0のみでRの演算を処理しているように見えます。
図1:R処理時におけるCPUの負荷状況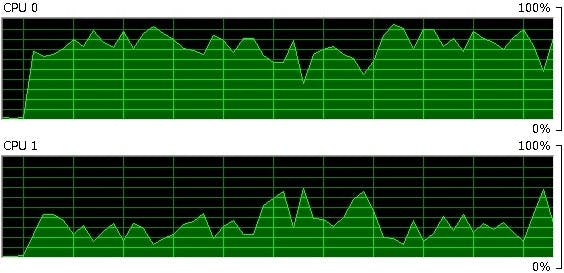
対象的に、図2で示すPythonの処理では、2つのCPUで均等に処理を分散しているのがお分かりいただけると思います。
図2:Python処理時におけるCPUの負荷状況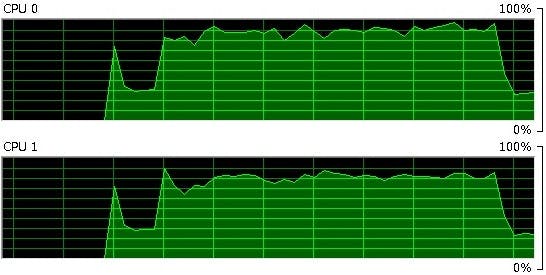
統計分析といえばRというのは現在最も一般的ですが、処理速度や外部処理との連携機能などを調査した結果、Pythonという選択肢も十分に魅力的であることがお分かりいただけたかと思います。もし、利用したい統計モデルがRだけでなくPythonでも実装されているようであれば、選択肢のひとつとして加えてみてはいかがでしょうか?
次回以降の連載テーマとして、今回取り上げたロジスティック回帰以外の分析手法に関してもPythonでの実装レポートを取り上げていきたいと考えています。
第1回 Python+Anaconda+Eclipseを導入
第2回 Python+Anaconda+Eclipseをインストール
第3回 PythonとRでロジスティック回帰の実装
第4回 PythonとRでロジスティック回帰の実行速度比較(今回)







