
目次
プロ野球データでロジスティック回帰分析を行った結果を公開します
本稿では、プロ野球の打席データで、実際にロジスティック回帰分析を行った事例を紹介します。具体的には、その打席が「安打」か「凡打」かの確率が、ボールカウント、ストライクカウント、アウトカウント、得点差、得点圏走者の有無などによって、どのように変わるのかの分析を行いました。
ロジスティック回帰分析のアウトプット
まずは、下の2つの表をご覧いただければと思います。これがロジスティック回帰分析のアウトプットです。表側がモデルに投入した変数で、「オッズ比」の列の数値が、その変数が1増えるごとに、安打の確率が何倍になるかになります。なお、このデータでは、打席の結果は、投手と打者との「勝負」という観点から、四球、犠打の打席は除き、安打か凡打かのみとしています。
表1 セ・リーグの分析結果
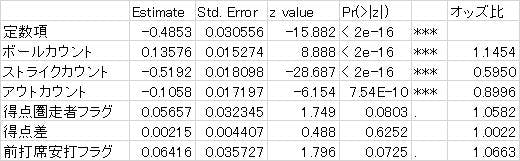
表2 パ・リーグの分析結果
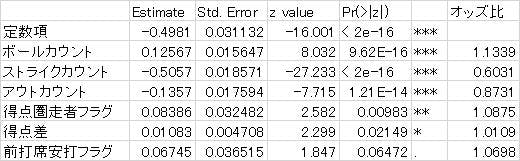
この2つの表から、大きく以下の5点が読み取れるかと思います。
まず、一点目は、ストライクを一つ取られるごとに、ヒットの確率は約0.6倍になるということです。別連載「プロ野球データでクロス集計 with Tableau」でもご紹介したのと、同様の傾向になります。2ストライクになると、0ストライクに比べて、ヒットの確率が0.36倍になるわけですから、打者から見ると非常に苦しくなるといえるでしょう。この辺は、実際の野球の試合を観たりプレーしたりされている実感とも、一致するのではないでしょうか。
二点目は、ボールカウントが1つ増えるごとに、ヒットの確率が約1.1倍になることです。これも、別連載「プロ野球データでクロス集計 with Tableau」でもご紹介しているものと、同様の傾向になります。「2ボール・1ストライクはヒッティングカウント」といったように、ボールが先行しているカウントでは安打が出やすいという結果が、ロジスティック回帰分析でも得られたことになります。
三点目は、得点圏に走者がいると、ヒットの確率は約1.06~1.09倍になるということです。セ・リーグは10%水準で、パ・リーグは1%水準で、統計的に有意になります。平均すると少しだけ安打の確率が上がるものの、得点圏に強い打者、弱い打者といった「個人差」の方が大きいというイメージかと思います。
四点目は、アウトカウントが1つ増えると、ヒットの確率は約0.88倍になるということです。アウトカウントを取れるということは、投手の出来がいいということなのか、アウトカウントが少ない方が、打者が心理的に気楽なために安打の確率が上がるのかなど、因果関係をどうとらえるかが、いろいろ考えられるところです。
最後に、五点目は、これまで述べた4点の傾向は、セ・リーグとパ・リーグで大きな差はないということです。これは2つの表を見比べると、係数の値が非常に近いことから、見て取れるかと思います。
なお、回帰分析でも同じですが、ロジスティック回帰分析における、各変数の「係数」を見る場合に重要なのは、他の変数の「コントロール」という概念です。具体的には、ストライクカウントが1増えるごとに、安打の確率が0.6倍になるというのは、モデルに投入した他の変数が、「全て同じ値」の場合にそうなるということを含意しています。そのため、説明変数同士が独立であることを仮定しています。
おわりに
ここで紹介した事例は、あくまでほんの一例です。本稿で紹介していた以外の変数もあり得ると思いますし、分析データの単位も本稿ではセ・リーグとパ・リーグとしましたが、球団ごとに行い、違いを見るといったことも考えられるかと思います。また、別の切り口や分析手法も、今後紹介してまいりたいと考えておりますので、ご期待くださいませ。
補論1:走者について
走者については、1塁、2塁、3塁のそれぞれに走者がいる場合を考えると、8通りのパターンになります。しかし、この8パターンをダミー変数にしてモデルに投入した場合には、良好な結果が得られませんでした。そこで、走者については、①得点圏内に走者がいる/いない、②走者そのものがいる/いないというダミー変数を想定することとしました。しかしながら、これら2つの変数は、相関係数が約0.7と強い相関があることから、両方をモデルに投入すると、分析結果に問題が生じてしまいます。このような現象を、多重共線性(multicollinearity。通称「マルチコ」。)といいます。そこで、最終的には、①のみ、すなわち、得点圏内に走者がいる/いないというダミー変数だけを、モデルに投入しました。
補論2:Rでのロジスティック回帰分析の実装
Rでロジスティック回帰分析を行う場合には、glm関数というものを使い、パッケージのインストールは不要です。具体的なコードは、以下の通りです。glm関数の括弧内は、まず、「目的変数~説明変数1+説明変数2+…+説明変数i」という形でモデルを記述し、カンマの後にデータソースの指定、次のカンマの後に、引数として、family=binomialを指定します。これは、二項関数という意味で、この引数を指定することで、ロジスティック回帰分析になります。後ろの括弧内の(link=”logit”)は、デフォルトと同じなので、入れても入れなくても構いません。なお、ここの引数を(link=”probit”)に変えると、計量経済学の分野でよく使われる、プロビット分析という分析手法を行うこともできます。
#データの読み込み
df <- read.csv(“xxxx.csv”)
#ロジスティック回帰分析の実行
res.glm.central <- glm(結果定義~ボールカウント+ストライクカウント+アウトカウント+得点圏走者フラグ+得点差+前打席安打フラグ,data=df, family=binomial(link=”logit”))
#結果の表示
summary(res.glm.central)
【連載記事】プロ野球データでロジスティック回帰の実践 with R
第1回 問題意識と分析手法
第2回 分析結果(本記事)
【当記事は、ギックス統計アドバイザーの中西規之が執筆しました。】

中西 規之(なかにし のりゆき)
ギックス統計アドバイザー。公益財団法人日本都市センター研究室








