
目次
大量データのテーブル結合時はテーブル結合に最適な形に保存先を分散させることが重要
前回は、Azure SQL Data Warehouse(以下、SQL DW)のリソースクラスの変更により、並列処理ができるクエリーのパフォーマンスチューニングについて説明しました。今回は、大量データのテーブル結合のパフォーマンスチューニングとして、”ハッシュ分散”について説明したいと思います。
なお、今回の記事は、「Microsoft|SQL Data Warehouse でのハッシュ分散と、クエリ パフォーマンスに与える影響」と「Microsoft | CREATE TABLE AS SELECT (Azure SQL Data Warehouse)」を参考に作成しています。合わせて読んでいただくことで理解が深まると思います。
SQL DWの大量データのテーブル結合が遅い理由
チューニングを行っていないSQL DWの大量データのテーブル同士の結合は、非常に遅いです。ビッグデータ用のAmazon Redshiftと全く比較にならないくらい遅く、最悪、クエリー(SQL命令)がフリーズします。まず、チューニング内容に入る前に、SQL DWのデータの記憶方法と何故遅いかを説明したいと思います。
SQL DWのデータはAzure Storage BLOBに分散保存される
SQL DWは、Amazon Redshiftのように実際の処理を行う”ノード”とデータを保存する”ストレージ”が1つに纏まっているわけではありません。SQL DWは、実際の処理はSQL DWで行い、データ保存先はAzure Storage BLOBになっています。このように処理と保存を分けることで、以前、ご紹介したような一時停止やスケール(処理速度)変更が素早くできます。
そして、このデータ保存先のAzure Storage BLOBは、下記のように内部で幾つかの”領域”に分散して保存されています。(図形はテーブル、アルファベットはデータの内容です) この様に分散することで、複数のノードで並列処理できるため、検索などの処理速度を上げることができます。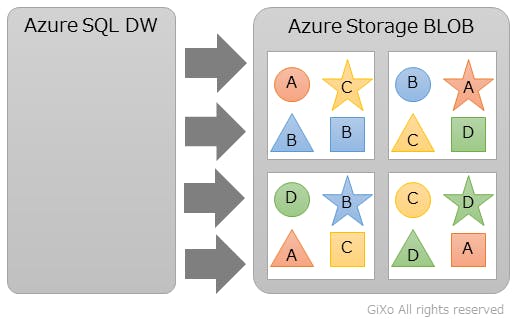
大量データのテーブル結合時にAzure Storage BLOB間でのデータ移動が発生する
標準のテーブルのデータ分散の方法は、ラウンドロビンを使用しているため、Azure Storage BLOBの各”領域”にだいたい均等に保存されています。通常の検索処理の場合は、並行処理を行う事ができるため、非常に最適な構造と言えると思います。
しかし、大量データのデーブル結合を行おうとした場合、Azure Storage BLOB内で結合結果の作成を行うため、Azure Storage BLOBの複数の”領域”でデータの移動処理が走ります。この時のデータ処理移動は、並行処理できないため、結合結果のデータ量に比例して処理時間が掛かってしまいます。
Azure Storage BLOB間でデータ移動が発生しないようにハッシュ分散させる必要がある
上記のようにテーブル結合のボトルネックは、Azure Storage BLOBの”領域”間のデータ移動です。このデータ移動を最小限にするため、Azure Storage BLOBの”領域”にテーブル結合で必要なデータを集める必要があります。そこで必要になるのがハッシュ分散です。
ハッシュ分散は、各テーブルの項目単位を設定します。例えば、売上情報の商品コードに対して、商品マスタや仕入マスタをテーブル結合する場合、対象テーブル(売上情報、商品マスタ、仕入マスタ)の商品コードに対して、それぞれハッシュ分散の指定をすることで、下記のようにAzure Storage BLOBの”領域”に同じ商品コードを持ったデータが保存されます。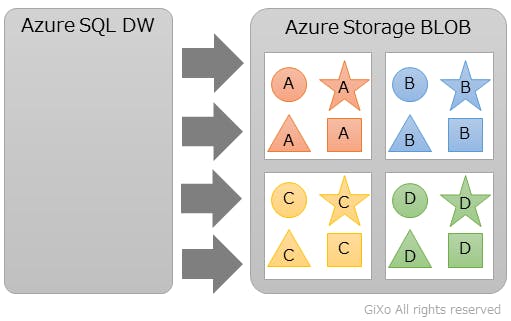
データ持ち方は異なりますが、Azure Storage BLOBのハッシュ分散は、Amazon RedshiftのDistkeyのような物だと思っていただければ良いと思います。
ハッシュ分散テーブル作成とデータ移動
普通にテーブルを作成した場合、ハッシュ分散デーブルにはなりません。テーブル作成時にハッシュ分散キー(項目)を指定することでハッシュ分散デーブルができます。そして、作成されたハッシュ分散デーブルにデータ登録を行うと、自動的にハッシュ分散キーの値が判定されてAzure Storage BLOBの”領域”に振り分け保存されます。また、ハッシュ分散キーの作成は、テーブル作成時のみで、テーブル作成後にハッシュ分散キーの作成/変更は行うことができません。
参考にしたページでは、下記のように通常のテーブル(dimCustomer)から「CREATE TABLE AS」でテーブルレイアウトの複製とデータ登録、ハッシュ分散キー(CustomerKey)の指定を同時に行っています。
|
1 2 3 4 5 6 7 |
CREATE TABLE myTable WITH ( CLUSTERED COLUMNSTORE INDEX, DISTRIBUTION = HASH (CustomerKey) ) AS SELECT * FROM dimCustomer; |
この方法は、最もシンプルな方法だと思います。しかし、ハッシュ分散デーブルへのデータ登録は、普通のテーブルに比べて何倍もの時間が掛かります。そのため、大量データを上記の方法で行おうとした場合、SQL DWがフリーズする場合があります。その場合は、下記のようにハッシュ分散デーブル作成後に、Where句でデータを絞り込んで複数回に分けてデータ登録する必要があります。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
--ハッシュ分散デーブル作成 CREATE TABLE t_pos ( uriage_date datetime, store_code char(2), kanri_no integer, goods_code char(13), item_count integer, uriage integer ) WITH ( CLUSTERED COLUMNSTORE INDEX, DISTRIBUTION = HASH (goods_code) ); --店舗ごとに分割してデータ登録 INSERT INTO t_pos SELECT * FROM t_pos_temp WHERE store_code = '10'; INSERT INTO t_pos SELECT * FROM t_pos_temp WHERE store_code = '11'; |
ハッシュ分散されたかを確認するためには、「DBCC PDW_SHOWSPACEUSED」コマンドを実行します。下記は、通常のテーブルと、そのデータをハッシュ分散テーブルに登録したデータの登録数です。ハッシュ分散テーブルへのデータ登録の結果、Azure Storage BLOBの一部の”領域”に対して、データが集中していることが分かると思います。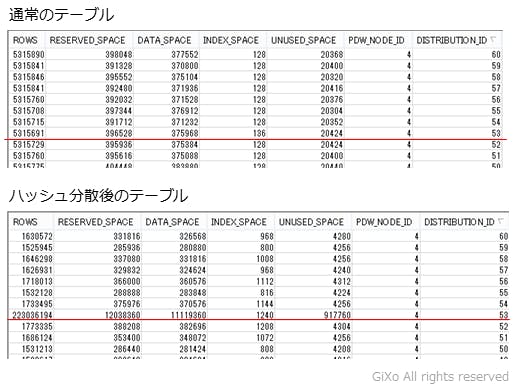
テーブル結合にはハッシュ分散テーブルの使用が必須
SQL DWで大量データのテーブル結合のためには、ハッシュ分散テーブルの使用は必須です。現段階(2016.01.25現在)の検証環境(*1)を使用して、テーブル結合の検証クエリー(*2)を実行した結果、通常のテーブルで約3時間20分掛かりましたが、ハッシュ分散テーブルを使うと約30秒で行う事ができます。しかし、ハッシュ分散テーブルの登録には非常に時間が掛かり、検証で使用したテーブルの登録に8時間ほど使用しました。つまり、テーブル結合は早くすることはできるが、その準備に多くの時間を必要とします。
SQL DWで大量データを登録する場合は、”とりあえず”データを登録するのではなく、テーブル結合を考慮したテーブル設計を事前に行う必要がありそうです。
(*1)検証環境:400DWU / largercリソースクラス
(*2)検証クエリー:約100カラム×約3.19億件のトランザクションテーブルから、約5000万件や約100万件など複数のマスタテーブルを結合し、3,100万件を取得するクエリー




