
表計算ソフトからの”脱皮”
BIシーンに大きなインパクトをもたらす可能性を秘めた「Power BI」。ギックスでも、これまで何度も取り上げてきました。(関連記事リスト:Microsoft Power BIはデータアーティストの武器となる )
本特集では、Power BIの特性/特長について、テクニカルエンジニアの視点で解説していきます。今回は「Power BIが何を変えたのか」を歴史を紐解きながら振り返ります。
Power BIが変えたもの
Power BI登場以前と、登場後では、何が変わったのでしょうか。まずは、下図をご覧ください。
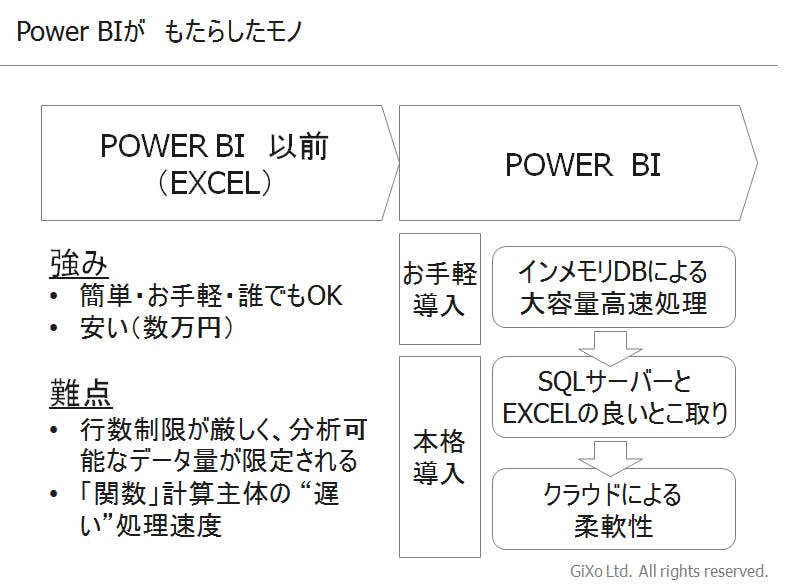
この構図を踏まえ、POWER BI が、果たして何をもたらしたのか、を見ていきましょう。
Power BI 以前
まずは、Power BI登場以前を振り返ってみましょう。
「Excelを用いたデータ分析」というと、まずピボットテーブルが思い浮かぶのではないでしょうか。非常に多くのビジネスシーンで利用されているExcelのユーザインターフェースは非常に強力です。実際、我々開発者も過去に「Excelピボットテーブルの様に操作できるUIを持った”BIシステム”を導入・開発してほしい」というお客様からのリクエストをたくさん頂戴してきました。
しかし、世の中にはエクセルとは異なる独自UIを持つ様々なBI製品が存在し、また、たくさんの企業に導入されています。なぜ、これまで「ExcelをコアとしたBI製品」がマーケットを席巻できなかったのでしょう?
これまでのExcelは、その製品スタンスとして「表計算ソフト」であり続けました。そのため、BI製品の基本スタンスである「大規模データ処理用データベース」を自身の機能として搭載してこなかったのです。(これはMicrosoftの製品ラインナップ上、AccessおよびSQL Serverが存在していたことが、影響していたと考えられます。)
ピボットテーブルを例にとって技術的なポイントを振り返ってみましょう。BI製品が「データの格納を、データベースで行っている」のに対し、Excelは「分析対象データの格納元は、あくまでExcelシート」であるという製品思想が”最大の違い”として浮かび上がります。
すなわち、これが「BIユーザとしては我慢できない」性能上の制約となります。
性能上の制約:
- 扱えるデータ量は、Excelシートの最大データ量に制限されており、BI製品と比べて圧倒的に少ない。(=Excel2003で65,536行・Excel2007以降で1,048,576行)
- データの処理方法は、データベース的な表操作ではなく、Excelシートの表操作であり、速度が遅い。(=ビックデータを扱う為の最適化は優先されていない。)
この制約が、「ビックデータ × ピボットテーブル」というソリューションの導入を阻害してきたのです。(逆にいうと、この要素こそが既存BIベンダの生命線であったとも言えます。)
Power BI
一方、Power BIは、非常に革新的な存在として登場しました。
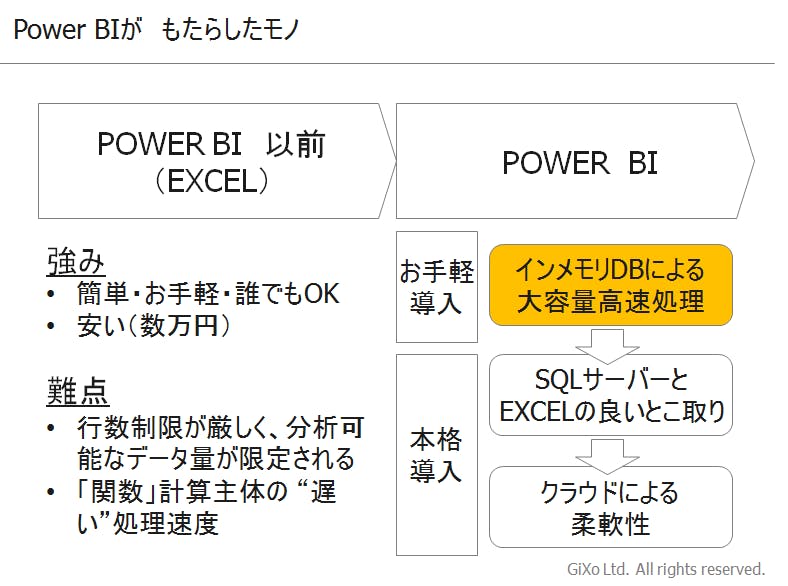
インメモリDBによる大容量高速処理(お手軽導入)
Power BI(PowerPivot)の進化の肝は、まさにこの「分析対象データの格納元は、あくまでExcelシートである」という思想を捨てた事にあります。
PowerPivotのデータ格納先は「イン メモリ データベース」です。(PowerPivotアドインを搭載したExcelは、内部に独立したデータベース機能を持っているのです。)これが前に述べた、「データ量の制限からの開放」と「ビックデータに最適化された高速処理」を可能としました。
データ量の制限からの開放
データ件数としての制限は存在しません。取扱いデータ量の上限は「イン メモリ データベース」当該マシンの搭載メモリ容量(=物理メモリサイズ)によって主に決定されます(*1)。つまり、搭載メモリを増やすことでスケールアップが可能なのです。尚、Microsoftは、搭載物理メモリの60~80%を分析可能データ容量として見積もることを提案しています。
ビックデータに最適化された高速処理
「イン メモリ データベース」の導入により、Excel上でのデータ操作処理は非常に高速化されました。このストレスのない処理スピードがExcelの持つ強力なユーザインタフェースをさらに圧倒的なものとしています。
「現業部門」には、お手軽導入がオススメ
つまり、PowerPivot(=Power BI お手軽導入)は、
- 速度が命
- 特別な知識を必要としない
- 何千万円ものお金はない
- ビックデータといってもテラバイトクラスのデータ量までは必要としない
という特徴を持っているわけです。PowerPivotの特徴は、各企業の「現場」に求められるBI業務に対して非常にマッチしていると言えるでしょう。
(参考)イン メモリ データベース とは?
大規模データ・高速処理・多次元分析といったBI業務に求められる要求を満たす為に、BI製品が搭載するデータベースにはいくつかのタイプがあります。前述の通り、PowerPivotは③:インメモリタイプに分類されます。それぞれの特徴を簡単にご説明することで、PowerPivotの目指すところをご理解いただけるのではないでしょうか。

①.ハードウェア最適化タイプ(Oracle Exadata・IBM PureData System など)
ハードディスクのアクセススピードやバススピードなど、ハードウェアの性能を突き詰めることで速度を上げるタイプです。多くの場合、専用ハードウェアとセットでアプライアンスとして提供されます。データボリューム・アクセススピードともに圧倒的なハイスペックを誇りますが、価格も圧倒的に高いです。
②.カラムナータイプ(Amazon Redshift など)
列指向データベースとも呼ばれ、一般的なDB(リレーショナルデータベース)が「行単位」でデータを管理するのに対して「列単位」でデータを管理するタイプです。対象となる一部の項目データを取得する為に行全体へのアクセスを行う必要がない為、巨大なデータを取り扱う上で「取り出し項目数は少ないが、取り出し件数は多い」場合には、非常に適しています。
また列単位でデータを格納するという特性上、分散処理との実装の相性が良好です。複数台のマシンでクラスタを構築し、ノード数をスケールアウトすることで全体性能を向上させることが容易だと言えます。
反面、システムの導入にはデータベースやクラスタに関する基本的な知識を必要とするため、導入のハードルは高くなります。
③.インメモリタイプ(PowerPivot・Apache Derby・Oracle Berkeley DB など)
一般的なDBがデータをハードディスクなどのストレージにデータを格納した状態で、ディスク→メモリ→CPUという手順でデータを転送して処理を行うのに対し、あらかじめ殆どのデータをメモリ上に格納した状態でDBのサービスを行うタイプです。
最大のボトルネックとも言えるディスクI/Oを極力抑えることで、「スピードが命」な業務に最適です。反面、扱えるデータの最大量が「メモリに依存」するため、データをディスクに格納する他タイプよりも劣ってしまいます。
また、データベースの起動時に殆どのデータをメモリ上に読み込む為、起動時間が比較的長いことにも注意が必要です。
④.キューブタイプ(Open OLAP・ Oracle OLAP Server)
ディメンションやメジャーといった、多次元分析に必要な要素をデータベースのレイアウトに色濃く反映させることにより、高速検索を実現するタイプ。言い換えれば多次元分析に特化したデータベースです。
他タイプに比べ、ハードウェアの性能を高く求められない、多くのOLAP製品が存在する、という事で、BIソフトウェアにおけるスタンダードな方式の一つとなっています。
分析の為のシステム構築(要件定義・設計・実装)および分析作業において、BIやOLAPの知識を必要とします。
今回は、「お手軽導入」で「どれだけ世界が変わったのか」をご紹介しました。次回は、最終回という事で「本格導入」についてご紹介します。
*1:搭載メモリ容量を超えるデータも、ストレージにキャッシュすることによって扱うことは可能なものの、速度が著しく低下し、製品としての魅力を損なうことから本記事では説明を割愛しました。
関連記事一覧はコチラからご確認ください。







