
この記事は GiXo アドベントカレンダー の12日目の記事です。
昨日は、pandas でヘッダーが複数ある POS データを縦持ち横持ち変換する(前編)でした。
Technology div. の緒方です。
本記事では前回の記事で書いたコードを書き換えて別の似たような形式のデータに対してすぐにコードを作れるようにしたいと思います。
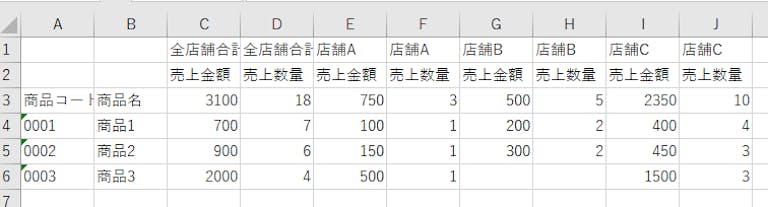
前回は次のようなデータを加工していきました。
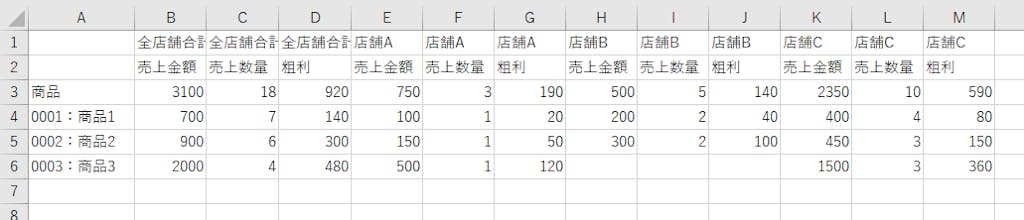
今回は少しだけ構成が異なる次のようなデータの加工もスムーズに行えるように処理を書き換えていきます。
今回の目標
今回はただ素直なテーブルに変形するだけではなく、なるべくコードの内容を変えることなく、スムーズに多くの種類のデータに対応できるコードを書くことを目標にします。
スムーズに多くの種類のデータに対応できるのは重要です。なぜなら扱うデータが高々数種類であれば1つ1つ実装しても大した工数にはなりませんが、数十、数百となれば1つ1つ実装しては膨大な時間がかかってしまうからです。
データの前処理というのはそれ自体は世の中に対してなんの価値も生み出さない行為です。前処理の後でデータの可視化なり機械学習なりで使用されて、さらにその結果として何らかの意思決定をしたりアプリケーションなどで使われて初めて価値が生まれます。このような理由からデータの前処理に工数をかけるべきではありません。
ここから先は工数を削減するということを意識しながら読んでみてください。
加工手順の見直し
工数削減を目指してコードを書き換えてみたいと思います。前回のコードは次のようなものでした。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
import pandas as pd # ファイルの読み込み df = pd.read_excel( 'サンプルデータ.xlsx', header=[0, 1], ) # 縦持ち変換 id_vars = list(df.columns[:2]) value_vars = list(df.columns[4:]) df = df.melt( id_vars=id_vars, value_vars=value_vars, ) # カラム名を変更する df.columns = ['item_code', 'item_name', 'store', 'sales_type', 'value'] # 横持ち変換する df = df.pivot_table( index=['item_code', 'item_name', 'store'], columns=['sales_type'], values='value', ) df.reset_index(inplace=True) |
今回新しく扱うサンプルデータ2では、前回のやり方に従うと、次のような処理を書けばひとまず素直なテーブルに直すことができそうです。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
import pandas as pd # ファイルの読み込み df = pd.read_excel( 'サンプルデータ2.xlsx', header=[0, 1], ) # 縦持ち変換 id_vars = list(df.columns[:1]) value_vars = list(df.columns[4:]) df = df.melt( id_vars=id_vars, value_vars=value_vars, ) # カラム名を変更する df.columns = ['item', 'store', 'sales_type', 'value'] # 横持ち変換する df = df.pivot_table( index=['item', 'store'], columns=['sales_type'], values='value', ) df.reset_index(inplace=True) |
2つのコードを見比べる
2つのコードを見比べた時に異なるコードが書いてある部分に注目してみます。異なるコードが書いてある部分は、データが変わるたびに書き換えなければならない部分です。そのような部分を減らせばコードを書く量を減らすことができるでしょう。
それでは、上記の2つとは異なる類似のデータが来た場合を想定して、変更される部分を変数として抜き出してみましょう。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
import pandas as pd # 変数は7つ PATH = 'サンプルデータ.xlsx' ID_VARS_NUM = 2 VALUE_VARS_NUM = 4 COLUMN_NAMES = ['item_code', 'item_name', 'store', 'sales_type', 'value'] PIVOT_INDEX = ['item_code', 'item_name', 'store'] PIVOT_COLUMNS = ['sales_type'] PIVOT_VALUES = 'value' # ファイルの読み込み df = pd.read_excel( PATH, header=[0, 1], ) # 縦持ち変換 id_vars = list(df.columns[:ID_VARS_NUM]) value_vars = list(df.columns[VALUE_VARS_NUM:]) df = df.melt( id_vars=id_vars, value_vars=value_vars, ) # カラム名を変更する df.columns = COLUMN_NAMES # 横持ち変換する df = df.pivot_table( index=PIVOT_INDEX, columns=PIVOT_COLUMNS, values=PIVOT_VALUES, ) df.reset_index(inplace=True) |
COLUMN_NAMES と PIVOT_XXXX で重複があるのが気になるところです。またそもそもカラムの中身に応じて名前を付けておかなければならないところも何とかならないでしょうか。解決策の1つとして、次のようなコードが考えられます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
import pandas as pd # 変数は3つ PATH = 'サンプルデータ.xlsx' ID_VARS_NUM = 2 VALUE_VARS_NUM = 4 # ファイルの読み込み df = pd.read_excel( PATH, header=[0, 1], ) # 縦持ち変換 id_vars = list(df.columns[:ID_VARS_NUM]) value_vars = list(df.columns[VALUE_VARS_NUM:]) df = df.melt( id_vars=id_vars, value_vars=value_vars, ) # カラム名を変更する df.columns = [i for i in range(df.shape[1])] # 横持ち変換する df = df.pivot_table( index=[i for i in range(ID_VARS_NUM + 1)], columns=[VALUE_VARS_NUM - 1], values=VALUE_VARS_NUM, ) df.reset_index() |
3つだけ変数を指定すれば別のデータにも対応できるようになりました。
課題点
さて、今のプログラムは果たして「正解」なのでしょうか。課題としては次のような点が挙げられます。
- 2種類しかデータを見ていないので新しいデータが来た時に大きくコードを変更する可能性がある
- 可読性が下がっている
1について、現実的に2つしかデータを見ていないためデータのパターンはつかみ切れていません。例えばヘッダーが3行ある場合に対応できていません。現実的には加工の対象となるデータがある程度出そろったうえで、可能な限りデータの構造を把握してから取り掛からないとコードを書き直すのに使う工数のほうが大きくなってしまいます。これは常にコードを書く量を減らすのが正解とは限らないことを意味しています。
2については例えば変数名が可読性を上げる要因になっていたのに変数を減らすことで可読性を下げています。また横持ち変換のあたりが直感的に分かりにくいコードになってしまっています。こうなると未来の自分や自分以外の人がコードを見た時に解読するだけで時間がかかってしまいます。
目先の手間にとらわれてコードを書く量を削減するのは誤りです。プロジェクト全体の工数を削減していくためにはデータの種類数やメンテナンスのやりやすさを考慮しながら実装していく必要があります。
終わりに
2日間にわたり pandas での縦持ち横持ち変換について記事を書いてきました。ここまで読んでくださっている方はおそらく日ごろから比較的複雑なデータも扱う業務に携わっている方が多いのではないでしょうか。
私自身、日ごろから多くの種類のデータを加工しています。時にはデータの複雑さに驚いてしまうこともあります。そのような日々の中で私が心掛けていることがあるので、最後にその心掛けを1つだけ紹介したいと思います。
私が心掛けていることは、「どんなデータであろうとそのデータを作った人は善人であり、必要に迫られてデータを作ったのであって悪意を持っているわけではない、と信じること」です。
様々なデータを加工しているとどうしてこんな形でデータを持とうと思ったのかと疑問に思うことがあります。私が見たデータの中には暗号なのかと疑うようなものもありました。そのようなデータを見たあかつきには頭を抱えたくなってしまうものですし、データを作った人を呪いたくなることもあるでしょう。しかし呪ったところでプロジェクトは進行しません。手を動かすしかないのです。それに実際のところデータを作った人が善人かどうかまでは分かりませんが、悪意を持っているわけではないというのは事実でしょうからますます呪う理由がありません。
先ほどの私の心掛けを持つことで淡々とデータの加工に取り組むことができます。結果としてプロジェクトが進めば価値を生み出す時間を多くとれるようになりますし、自分自身の精神衛生も保たれるのでみんな得です。呪いがちな人はぜひ一度お試しください。
明日は「すごいぞDataForm」を公開予定です。
Satoshi Ogata
Technology Div. 所属
データ分析基盤やデータの前処理について情報発信します。









