
各種回帰分析の実施方法を解説
本連載では、回帰分析の実施方法について、5日間に渡り説明してまいります。第2回目の本日は、重回帰分析について説明していきます。
回帰分析における回帰直線の引き方
重回帰分析に入る前に、まず重回帰分析の理解の前提となる回帰分析(線形単回帰分析)における、最も当てはまりの良い直線(回帰直線)の計算方法について説明します。
下の散布図を例にとってみましょう。散布図にプロットされた点は、多少のバラツキがあるものの、全体としては右肩上がりの傾向を示しています。「回帰直線の計算」というのは、このような時、散布図の点に最も当てはまりの良い右肩上がりの直線(青線)を数学的に求めるということです。具体的には、赤線のように、それぞれの点から、求める直線に垂直に線を引き、全部の点の「距離の長さの合計」が最も小さい値をとる直線を、最も当てはまりの良い直線とします。しかし、実際に距離を数学的に求めるのは、技術的に多少難しい部分があるため、便宜的に、「距離の二乗の合計」が最も小さい値を取る直線を計算し、これを最も当てはまりの良い直線としています。これを、「最小二乗法」といいます。
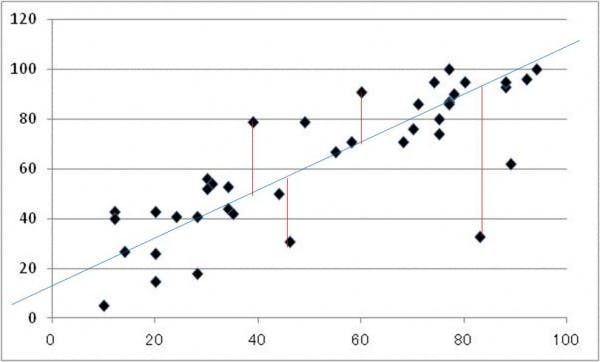
図1 回帰直線のイメージ
重回帰分析とは?
回帰直線の引き方をご理解いただきましたので、いよいよ、重回帰分析について説明です。前回同様、データを例に説明していきます。この事例の場合、「結果=ビール販売額」(被説明変数)までは前回と同じですが、原因(説明変数)が、「気温」と「湿度」の2つになっていることが異なっています。目視でわかる傾向としては、『①気温が高いほど、ビール販売額は高い』『②気温が同程度の場合、湿度が高い方が、ビール販売額が高い』ということが読み取れるかと思います。今回は変数が「ビール販売額」、「気温」、「湿度」の3つなので、上述の回帰直線の引き方で説明したような散布図で表現することはできませんが、こうした傾向を数式で表現したものが、重回帰分析になります。
表1 天候とビール販売額
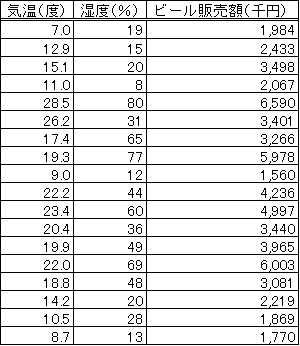
(出所:柏木吉基(2006)『Excelで学ぶ意思決定論』(オーム社)p.94)
重回帰分析(線形重回帰分析)の結果は、
Y(ビール販売額)=86.8X1(温度)+41.7 X2(湿度)+380
といったように、
Y= b1X1+b2X2+b3X3+・・・+biXi+b0
という、i個の説明変数をもつ一次関数の数式で表現できます。
なお、分析そのものは、Excelで簡単に行うことができます。ご参考までに、Excel2013でのアドインの使い方をご紹介いたします。
(http://office.microsoft.com/ja-jp/excel-help/HA102748996.aspx)
重回帰分析の結果の読み方
一番基本的な「係数」の読み方については、説明変数の数が1個からi個(上記事例の場合は2個)に増えただけで、大きな違いはありません。
これは単回帰分析も重回帰分析も同じですが、計算して得られた係数が、統計的に意味があるかどうかと、回帰分析のモデルそのものが、統計的に意味があるのかどうかの両方について、確認をする必要があります。これを、統計的検定といいます。
係数については、下表の係数の横にある、「P値」というところを見ます。Pはprobability(確率)の略で、説明変数の係数がゼロ、すなわち被説明変数に影響を与えていないと仮定したときに、得られた係数の値がどれくらいの確率で発生するかを求めたものです。これが、限りなくゼロに近ければ近いほど、ゼロと仮定したときにはありえない値、すなわち、その係数は統計的に意味があるということになります。一般的には、5%未満であれば、その係数は統計的に意味があると判断することが多いです。
表2 重回帰分析の分析結果
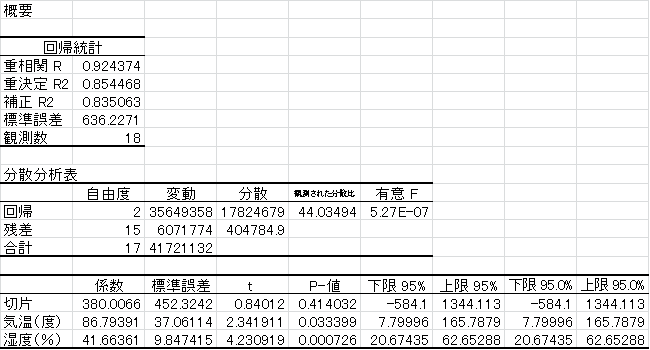
(出所:柏木吉基(2006)『Excelで学ぶ意思決定論』(オーム社)p.96)
モデルについても、同様に統計的検定をすることもありますが、モデルそのもののP値が5%以上ということはまずないので、主に「決定係数」という指標で判断します。これは、統計的には、説明変数が被説明変数の分散を何%説明しているのかを示していることを説明する指標といわれています。また、単回帰分析の場合には、決定係数は、説明変数と被説明変数の相関係数の二乗と一致します。
重回帰分析のメリットと注意点
重回帰分析の大きなメリットに、推定により得られた係数は、他の説明変数の影響を含まないことから、その説明変数の純粋な「効果」がわかるということです。これを、他の説明変数を「コントロール」したものということもあります。これは、多重クロス集計をカテゴリ変数でなく、連続変数で行ったものと同じようなことといえます。
重回帰分析の説明変数の中に、「男性=0、女性=1」といった形で、カテゴリ変数を投入することがあります。これを、ダミー変数といいます。ダミー変数は、連続変数とカテゴリ変数を同時に分析するという点では非常に便利ですが、例えば、男性と女性で大きく異なる傾向がある場合には、男女別々に回帰分析を行った方が正確な結果が得られます。
なお、説明変数同士に強い相関がある場合、回帰分析の結果が不安定になるという問題があります。これを、「多重共線性」といいます。詳細な説明は紙幅の関係上省略いたしますが、一般的には、説明変数同士の相関係数が0.5以上なら注意、0.7以上なら避けるべきと言われています。
- 回帰分析とその応用① ~回帰分析は何のために行うのか?
- 回帰分析とその応用② ~重回帰分析(今回)
- 回帰分析とその応用③ ~ロジスティック回帰分析
- 回帰分析とその応用④ ~スコアリング
- 回帰分析とその応用⑤ ~非線形回帰分析
関連記事一覧はコチラから
【当記事は、ギックス統計アドバイザーの中西規之が執筆しました。】

中西 規之(なかにし のりゆき)
ギックス統計アドバイザー。公益財団法人日本都市センター研究室






