
Cloud Machine Learning Engine は実行環境を提供するだけ
数年前まで機械学習は導入のハードルが高く、誰でもできるものではありませんでした。しかし、Python言語の機械学習用の機能追加などによって、高度な専門知識がなくても分析できるようになりました。その背景にはクラウドサービスの機械学習サービスの貢献が大きく、AWSやAzure、DataRobotなどではノンプログラミングで大量データでも機械学習が開発・実行できるようになってきました。
そして、Google Cloud Platform (以下、GCP)でも、機械学習専用サービスとして Cloud Machine Learning Engine (以下、ML Engine)がありますが、ちょっと調べても何ができるのか分からないのが実情です。今回は、ML Engine は何者かについて、さらっと説明したいと思います。(プログラミングや機械学習工程の具体的な説明なしです)
Cloud Machine Learning Engine は何ができるのか?
ML Engine を一言で説明するなら「機械学習を実行するためのクラウドサービス」です。そのため、DataRobotなどの他のクラウドサービスのようにサービス上で開発は行えません。
ML Engine を使って機械学習するためには、必要なデータをGCP上にアップロードし、事前に開発したPythonファイルを ML Engine にアップロード&実行します。そのため、他クラウドサービスのようなGUI開発環境はなく、GUIで ML Engine の存在を確認できるものは、GCPのWeb管理画面で確認できるトレーニングや予測の進捗状況ぐらいです。
若干、利用者側からすると ML Engine は不親切なサービスですが、Googleが開発した機械学習ライブラリのTensorFlowの処理を高速、かつ安価に実行できるため、大量データを処理するためには ML Engine の存在は非常に重要になります。
Cloud Machine Learning Engine を使うために抑えておきたい制約事項
ML Engine は機械学習を高速に実行するためのプラットフォームです。そして、プラットフォームには制約が付き物ですが、ML Engine の場合はこの制約が結構厳しい感じがします。
まず、初めにパッケージ(ライブラリ)のサポート範囲です。パッケージによってPythonができる事が決まりますので、ML Engine で実行する場合はそのサポート範囲内でPythonをプログラミングする必要があります。サポート範囲を見ると、当然の事だろうがChainerはサポートしていないらしく、現時点では Python 2.7 や TensorFlow 1.2 など一世代の前のバージョンしかサポートしていないようです。工夫するとパッケージ追加・変更もできそうな気もしますが、既存の ML Engine のパッケージに合わせてプログラミングした方が良いと思います。(参考:ML Engine のサポート範囲)
また、ローカルPCや仮想マシンなどで機械学習を行っていると「入出力ファイは何処に置くの?」と気になると思いまが、「全ての入出力ファイルはクラウドストレージ上に置く」が答えです。
ML Engine では、トレーニング、予測結果だけでなく、トレーニングの結果などもクラウドストレージを使って処理を行っています。そのため、ローカルストレージが存在しないようです。機械学習ではpandasなどでローカルファイルを使って、機械学習で処理するデータの下準備を行うことが多いと思いますが、ML Engine で同様の事を行おうとした場合、大幅な修正が必要になるかもしれません。
以上の事から、ML Engine で機械学習を行う場合は「可能な限り別プロセスでデータの抽出・集計・構造変更を行った後、機械学習に最適なデータだけで ML Engine に処理を依頼」した方が良さそうです。この様にML Engine で実行するプログラムを「データの下準備」と「機械学習本体」に分けることで、データの下準備側ではPythonパッケージや入出力インターフェースに縛られなくなり、機械学習本体側では処理をシンプルにすることができます。
データの下準備はどこで行うか?
では「ML Engine で使用するためのデータの下準備は何処でするのか?」ですが、データの下準備をする環境を構築するためには以下の壁などがあると思います。
- それなりのマシンスペックが必要
- GCP上のクラウドストレージなどをシームレスに使いたい
- そもそもPythonの開発・実行環境を作るが面倒だ!
これらを解決するのがクラウドサービスの Google Cloud Datalab (以下、Datalab)です。Datalabを簡単にいうと「仮想マシンに Jupyter Notebook が入った開発環境」です。
Datalabは、GCPのユーザー認証が取れた 仮想マシン(Google Compute Engine)上で動作します。これによって、マシングレードを処理用途によって設定可能になり、ユーザー認証が行われているため、ID/パスワードなしでクラウドストレージなどに専用コマンドを使って接続できます。そして、Jupyter Notebook は、機械学習に適したGUIベースの代表的なPython開発環境です。これらの機械学習に必要な環境がDatalabを使用することで簡単に用意することができます。
このDatalabを機械学習のハブとして利用することでで、GCP上のクラウドストレージなどからデータを掻き集め、データを加工・アップロードし、ML Engine に処理を依頼し、最後に予測結果を確認するという一連の作業をDatalab上で行うことができます。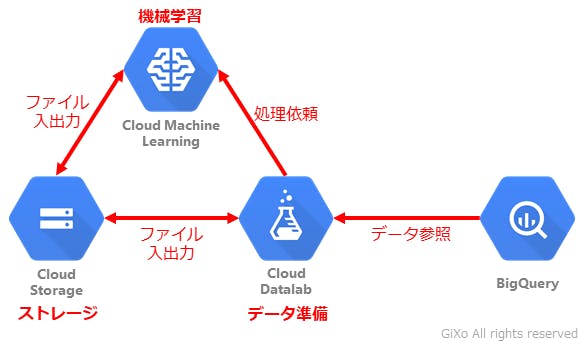
シーンに応じて機械学習の実行プラットフォームを変える
このように ML Engine はパワーはあるが、ストレージやPythonパッケージなどの制約があり、クイックに機械学習ができるサービスではありません。
そのため、データ量がそれほど多くない場合は、Datalab単体で機械学習を行っても良いと思います。DatalabにはGPUも追加できますので機械学習だけでなく、Deep Learning でもある程度の処理は行えると思います。
また、機械学習のデータがAWSなどの別のクラウドサービスに存在する場合は、同じクラウドサービスの仮想マシン上に Jupyter Notebook 環境を構築した方がデータ転送やセキュリティー面で有利になります。多少、環境構築が面倒ですが、Jupyter Notebook や TensorFlow はオープンソース、かつ導入事例も多いため、ちょっとWeb検索をすれば環境構築のヒントは転がっています。
この様に最初から ML Engine を使わずに、例えば初期のモデル決めはDataRobotで行い、データ構造変更が必要になったらDatalabで開発を行い、最終的には ML Engine で大量データ処理&システム化のように機械学習のプロジェクト進捗によって実行プラットフォームを変えても良いと思います。








