
AWS Glue がフルマージドしているのはETLのプロセスではなく動作環境
データ分析ではデータベースを使うことが多く、そのデータベースにデータを入れるためにはETL処理は必要不可欠な処理です。ETL処理をフルスクラッチでプログラミングしても良いのですが、作業を効率化するためにETLツールを使うことが多いです。この波はローカルツールだけではなく、クラウドサービスにも広がり、Google Cloud Dataprep などが発表されてきました。そして、AWSでもETLサービスである「AWS Glue (以下、Glue)」が一般公開されましたので、早速、軽く触った感覚でご紹介したいと思います。
AWS Glue とは
Glueの説明の最初を見ると「AWS Glue は抽出、変換、ロード (ETL) を行う完全マネージド型のサービスで~」とあるので、TalendのようなGUIベースでコンポーネントを配置するものか、Google Cloud Dataprep のよう表形式上でデータ変換するものかと思うかもしれませんが、全く違いました。
Glue を一言でいうなら「ETL処理を支援してくれるフレームワークサービス」です。そのため、Glueからの操作だけでは複雑な処理はできません。GlueでETL処理を開発するのは、Glueの各機能を使用して「処理に必要な素材を集め、処理の外枠までウィザード形式で大まかなプロセスを作成し、最後に自動生成したプログラムをカスタマイズ(コーディング)する」という流れになります。そのため自動生成されるPythonプログラムのスキルは必須になります。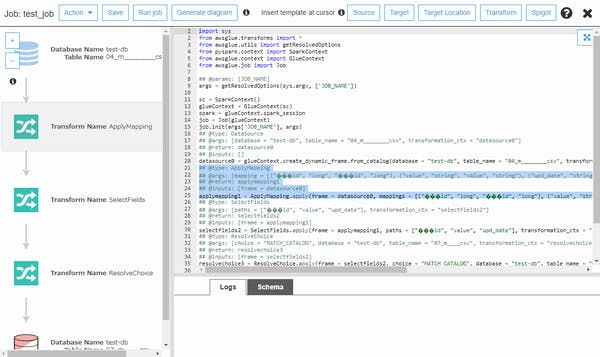
ETL処理の外枠までは半自動生成
Glueは以下の3つの主要機能があり、ETLプロセス開発・実行の支援をしてくれます。
- データカタログ:入出力となるデータ定義のメタデータリポジトリ
- ETLエンジン:Pythonコード自動生成・実行
- スケジューラー:ジョブ実行・監視
データカタログ
GlueではETL処理の対象となるクラウドストレージ上のデータやクラウドデータベースなどのデータ定義情報を「データカタログ」という形でGlue内のデータベース内でリスト管理しています。そして、ただリスト管理しているだけではなく、Glueクローラーによってリスト収集、データ定義の自動判定をやってくれるところです。
Glueクローラーは Amazon S3 (クラウドストレージ) などの収集対象に対して、定期的、または任意のタイミングでデータ定義を取りに行きます。対象となるデータはCSVなどの構造化データ以外にもJSONなどにも対応し、GZIPで圧縮していてもデータ定義を自動判定してくれました。ざっと見た感じでは精度はそれなりの物でした。(Shift-JISは文字化けするなど日本語に弱いところはあるけど)
データ定義はクローラー収集後でも追加・修正可能で、データカタログは Apache Hive メタストアと互換性があるらしく、同様にHive技術を使っているデータレイク関連の Amazon Athena、Amazon EMR、Amazon Redshift Spectrum とデータカタログのデータ統合できるらしいです。そのため、GlueをETL処理で使わなくてもデータカタログ機能だけでも十分価値はあると思います。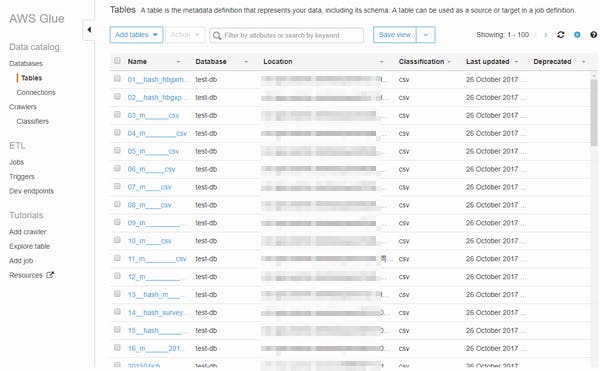
ただ、残念なことにAWSの東京リージョンではGlueは使えません。そのため、Amazon Redshift や Amazon RDS などが東京リージョンにある場合は参照できませんでした。(Amazon S3 は大丈夫でした)
ETLエンジン
Pythonコードを自動生成し、それをジョブとして実行する環境を提供するETLエンジンですが、コードの自動生成はウィザード形式で入力ソース、出力ターゲットなどを選択し、最後にデータ項目のマッピングまで自動的にやってくれます。単純な処理でしたら自動生成したコードだけETL処理を実行できると思いますが、値の編集やフィルタリングが必要な場合はプログラミングが必要になります。
スケジューラー
上記で作成したジョブの実行・監視、エラー時のリトライなどを行います。ジョブはスケジュールによって定期実行でき、こちらもウィザード形式で簡単に設定できます。また、AWS Lambda と連結することで「S3にデータファイルがつかされたらGlueジョブ実行」のようなイベントによる起動もできるらしいです。
最後は技術者の腕次第
Glue クローラーやETLエンジンによって、ETL処理のExtract(抽出)とLoad(データロード)は、ほぼ自動的に作成することができます。あとはTransform(変換・加工)に集中するだけです。
Glueはフルマネージドの Apache Spark 上で動作します。そのため、大量データでも高速に処理できるはずですが、ただプログラミングすれば良いものではありません。Sparkで処理するためには並列分散処理を意識することも必要ですが、Spark用のPySpark、GlueのカスタムETLライブラリの知識がないとGlueの性能を出し切れないようです。
GlueはETL処理のTransform(変換・加工)をプログラミングすることで処理の自由度を上げた分、他のETLツール(サービス)に比べて導入の技術ハードルは高くなってしまいました。
サーバーレスのバッチ処理ができるかも?
GlueはETLサービスとしての位置付けでしょうが、Glueクローラーは他のAWSサービスと組み合わせることでデータレイクの運用が楽になるかもしれません。
また、GlueはAWS Lambdaのような処理のタイムアウトがないため、サーバーレスのバッチサービスとして利用できるのではと期待しています。AWSにはバッチサービスとして、AWS Batch がありますが、このサービスを使用するためにはクラウドサーバー(Amazon EC2)を起動している必要があります。しかし、Glueには常に起動しているサーバーは存在しません。そのため、ELT処理(データベース上で変換・加工処理を行うETL処理)などのデータベースのSQL処理だけで変換・加工処理が完結するタイプのバッチ処理ならGlueで簡単、かつ安価に開発・運用できるかもしれません。
次回は、しっかり勉強して、この辺の開発方法についてお伝えできればと思います。(暫く先に事になりそうですが…)







