Firestoreのサブコレクション活用にあたって
本連載ではFirestoreの魅力について書いていきたいと思います。
弊チームの Web アプリケーションは基本的にFirebaseへデプロイしていますが、Firebaseを選択している理由としてFirestoreの存在は大きいです。弊社プロダクトのトチカチでも稼働中ですので、その事例も含めご紹介していきます。
本記事の前半ではFirestoreの概要を書いており、後半ではFirestore主要機能の1つであるサブコレクションについて書いています。
Firestoreの概要
Firestore は NoSQL ドキュメント指向データベースと呼ばれています。 Firestore から取り出せるデータ構造はオブジェクトモデルであり、ドキュメント指向データベースではこのオブジェクトモデルがドキュメントにあたります。
私の Firestore のドキュメントに対するイメージは、セキュアにクライアントから直接アクセス可能でスケーラブルな JSON です。
私にこうしたイメージを持たせたのは、Firestore に次のような機能があるからです。
1. サブコレクション
Firestore では各コレクションのドキュメント配下にサブコレクションを用意して、階層を掘り下げていくことが可能です。(最大で100レベルまで)
ツリー構造での直感的なデータモデリングが可能になっており、他のNoSQLにはないFirestoreならではの機能です(2020/5/11現在)。また、Firestore独自のセキュリティルールにより、役割に応じてサブコレクションを設計することも可能です。取り扱いが難しい部分もありますが、自由度が高いからこそできることが多くあります。データモデルの設計がUXにもDX(Developer Experience)にもセキュリティにも大きく影響するため、ここがFirestoreの楽しくも難しい部分だと思います。
なお、最初にJSONと近いデータ構造と書きましたが、もちろん異なる点はあります。コレクションとドキュメントを交互に持たせなければならなかったり、ドキュメント1件あたりのサイズが1MB以下に制限されていたり、扱えるデータ型も少し異なったりします。ただ、私の場合はそれらの違いで不便を感じたことはあまりありません。タイムスタンプや緯度経度情報はそのまま入力できますし、リファレンスと呼ばれるFirestore内のパスを値として格納できるので、任意のオブジェクトにワープすることもできます。
ただし、JSONと同じノリでデータモデルを設計してしまうと、Firestoreのアンチパターンにハマることがあります。Firestoreの特性をちゃんと理解していれば必然的に避けられる問題ですが、私は開発初期に見事にハマりました。詳細は後半に書きます。
2. クライアントからの直接アクセス
Firestore はクライアントからの直接アクセスが可能です。
一般にアプリケーション開発で DB を組み込むとなれば、クライアントと DB を直接つなぐことはなく、セキュアに守られたサーバーサイドの裏に隠蔽するのが普通でしょう。
しかし Firestore では独自のセキュリティルールを用いることで、クライアントから直接 DB(Firestore)へアクセスすることを可能にしています。フロントエンドでの使い方に合わせてセキュリティレベルを調整することも可能です。
フロントエンドで DB 管理下のデータが必要となった際も、フロントエンドのロジック内で Firestore SDK を操作して、直接データを取り出すことができます。サーバーサイド API を別途用意してあげるなどはせずに、です。
3.サーバーレスかつスケーラブル
Firestore の利用を開始する上で、こちらがサーバーやインフラの準備をする必要はありません。サーバーの運用や保守について考えることも特にありません。もちろん前述のセキュリティルールは超重要ですが。
仮に大量のアクセスが想定される場合でも、事前にこちらで Firestore がそのアクセスに耐えうるように調整しておくことは特にありません。read/write の制限や従量課金による費用増大などがあるので、そこの考慮は必要です。
アプリ開発において上記の様な状態が当たり前になると、少なくとも自分はこれらがない世界に戻るのがなかなか困難です。
なぜ BigQuery のデータをクライアントから直接取り出せないんだ?なんてことをふと思ったりもします。パラダイムシフトですね。
他にもトチカチでは、リアルタイム・リスナー機能のおかげで機械学習モデリングの結果をリアルタイムにレポートへ反映させることができています。Firestore様様です。
前置きが長くなりましたが、今回はFirestoreのサブコレクション活用における注意点を書いていきます。
他のFirestoreの機能を使ってどんなコンテンツやUXを実現できるかは別の記事で紹介予定です。
Firestoreのサブコレクション活用における注意点
サブコレクションの概要は先に説明した通りですが、公式ではコレクションはドキュメントのコンテナと言われています。

コレクションのコンテナの中に、さらにコレクションをネストしていけるのがサブコレクションです。JSONでは表現できないですが、イメージとしては下記の様な感じでしょうか。
|
1 2 3 4 5 6 7 8 9 10 11 |
{ collectionID1: { documentID1: { key1: value1} // Field documentID1: { subCollectionID2: { documentID2: {} } } documentID3: { key2: value2} // Field } } |
作成したデータモデルを活用する上で注意すべきポイントを2つご紹介します。また、サブコレクションによりどんなデータモデルが作成可能かについても軽くご説明します。
サブコレクション活用にあたり注意すべき2ポイント
繰り返しになりますがFirestore はスキーマレスなサービスであり、データモデル設計の自由度は高いです。しかし、そこに落とし穴があります。
落とし穴にハマらないための、私が考えるポイントは下記の2つです。
- 同一コレクション直下のドキュメントにバラバラのフィールドを持たせない
- コレクションはドキュメントの総称(コンテナ)。データモデルを設計する際、コレクションは変数として考えない。
この2つは注意点としては初歩だと思いますが、Firestoreの特性を踏まえたデータモデルを事前にちゃんと設計できていないとハマります。
それぞれ説明していきます。
1. 同一コレクション直下のドキュメントにバラバラのフィールドを持たせない
なぜこれをすべきでないかというと、単純に管理しにくいからです。Firestore では同じ階層のドキュメントフィールドが統一されていないと、リレーションに対するクエリとセキュリティルールの取り扱いが困難になります。簡単な例を示します(コードは公式ドキュメントより)
|
1 |
docs = db.collection(u'cities').where(u'capital', u'==', True) |
こちらのwhereを使ったクエリでは、citiesコレクション配下のドキュメントの中で、フィールドのcapitalがTrueであるものへ絞り込んでいます。
Firestoreのクエリの起点となるリファレンスオブジェクトの都合上、基本的には同一階層のドキュメントに一律でクエリの条件が適用されます。よって、citiesコレクション配下のドキュメントのフィールドがバラバラであった場合、この様に Firestore に用意されたクエリを使って欲しいデータを絞り込む・取り出す、ということが難しくなります。
セキュリティルールについても同様です。セキュリティルールでは特定のフィールドの値を使ってセキュリティの条件を記述することができます。セキュリティルールは同一階層に対して一律で適用されるため、異なるフィールドが混在しているとセキュリティに穴が空く可能性が高まります。
サブコレクションを使い始めると、様々な階層のドキュメントを管理し、クエリやリファレンスを使ってアクセスすることになります。それらの管理負担を軽減するには、スキーマレスといえども最低限のルールが必要になります。
といっても、クエリやセキュリティルールの対象としたい共通フィールドを持たせつつ、一部異なるフィールドを入れることはあります。これはスキーマレスのメリットなので、バランスよく活用したいですね。
続いて2つ目のポイントです。
2.コレクションはドキュメントの総称。データモデルを設計する際、コレクションは変数として考えない
これは初期の検討段階で、FirestoreをJSONライクに扱おうとして気づいたポイントです。私は無意識に、コレクションとドキュメントを異なるオブジェクトとして捉えたデータモデルを設計していました。
このポイントを押さえないと、Firestoreの一部機能を全く活かせないデータモデルになってしまうため、私的アンチパターンです。ただ当たり前すぎることなのか、公式には特に記載がありません。(前述の通り、Firestoreの特性を理解していれば必然的に避ける設計ではあります)
弊社プロダクトのトチカチのデータモデルを少し簡単にして説明します。
トチカチでは開発初期に下記の様なデータモデルがありました。
当時はFirestoreもデータモデル設計も初めてで、「あまりネスト深くしたくないしとりあえずこれにするか〜」くらいの考えでした。
|
1 2 3 4 5 |
// {}がついてるのは変数 collection: User - document: {userId} - subcollection: {PurchaseAreaID} - document: {yyyymm} |
このモデルは、「あるユーザーはどのエリアの何月分のデータを購買したか」という状態を表そうとしています。サブコレクションである{PurchaseArea}にはエリアID(変数)が入り、その配下のドキュメントIDには年月(変数)が入ります。
イメージにすると下記の様な感じです。

ユーザーは複数のエリアを購買しますし、同じエリアについて異なる月のデータを購買します。
よって、ユーザーが新しいエリアを購買するたびに「サブコレクションである PurchaseAreaId-Aが増える」「PurchaseAreaId-A配下の yyyymm が増える」という状態になります。
この状態が私的アンチパターンです。詳しく説明します。
先に自分の中での答えを書いておくと、
- コレクション(サブコレクション)は新しいデータモデルが誕生しない限り増えない(上記例で言えば、ユーザーの購買などによる状態変化によってコレクションが増えてはいけない)
よって、正解のデータモデルは
|
1 2 3 4 5 6 |
collection: User - document: {userId} - subcollection1: PurchaseAreaId - document: {areaId} - subcollection2: Yyyymm - document: {yyyymm} |
となります。イメージは下記の通りです。

先に書いた通り、コレクションとはコンテナでありドキュメントの総称です。ドキュメントがもつフィールド群がなんであるかを示す名称であり固定値です。
最初に例として載せたNG モデルにおいて、サブコレクション名は変数になっていました。
これの何が困るかというと、まずクライアントは SDK を使ってサブコレクションPurchaseAreareaIdの一覧を取得することができません。クライアント SDK にはコレクションをリストアップするメソッドは用意されていないからです。
よって、変数コレクションであるPurchaseAreaId配下のドキュメントを取得するパスを指定するには、ハードなPurchaseAreaIdをなんらかの方法で事前把握しておく必要があります。変数としてパターンが増加する可能性があるにもかかわらずです。
(サーバーサイドのSDKにはコレクションリストを取得するメソッドが存在するのですが、セキュリティの問題もありクライアントSDKには存在しないのでしょう。ただクライアントに存在しない時点で、Firestoreは1つ目の様なデータモデルを想定していないともいえます)
userIdドキュメントのフィールドにPurchaseAreaIdのリストやリファレンスを持たせて参照することはできます。しかしこの場合、新しいコレクションが作成されるたびに userId ドキュメントをupdateしないと整合性が取れなくなりますし、特定のサブコレクションにアクセスしたい場合は毎度userId ドキュメントを読み取る必要があります。また、多量のエリアを購買するuserIdのフィールドはどんどん肥大化していきます(ドキュメントのサイズ上限は1MB)。
サーバーサイド API にコレクションをリストアップしてもらって、それを受け取る方法もありますが、userId ドキュメントを読み取るのと同じく、そうした操作が必要になった時点で設計を見直すべきでしょう。本記事では触れませんが、UIに描画するために必要なFirestoreデータの読み取りは原則クライアントから行うべきだからです。
また、Firestore のセキュリティルールでは変数であるPurchaseAreaIdに対してセキュリティルールを抽象的に設定することができません。セキュリティルールを記述する際、ドキュメント ID には変数を設定できますが、コレクション(サブコレクション)には変数を設定できず、ハードに値を書いてあげる必要があります。(詳しくは公式ドキュメントを読んでいただくのがよいです)
|
1 2 3 4 5 |
// firestore.rules // {}で囲まれた文字列は変数扱いになるが、UserとAreaIdの箇所(コレクション)には{}を使うことができない match /User/{userId}/AreaId/{areaId} { allow hoge; } |
つまり変数をコレクション名に適用した場合、変数によって新たなコレクションが生成されるたびにセキュリティルールにも新しい変数の値をハードに記述しなければなりません。変数のパターンが 100 個あれば、100 個のルールを書いてあげる必要があります。セキュリティルールの必要ないコレクションであればその限りではないものの、これは設計の欠陥以外の何者でもないでしょう。。
一応サブコレクションであれば、その親のコレクション(サブコレクション)と共通のセキュリティルールを適用することは可能ですので、完全な無秩序になる訳ではありませんが、技術的負債の芽となることは確実です。
ちなみに変数をコレクションに設定した時点で、私が描いていたデータモデルとは異なるデータモデルを定義してしまっていることがわかります。
最初のイメージ画像は少しミスリードしており、実際は下記の様なデータモデルになっています。
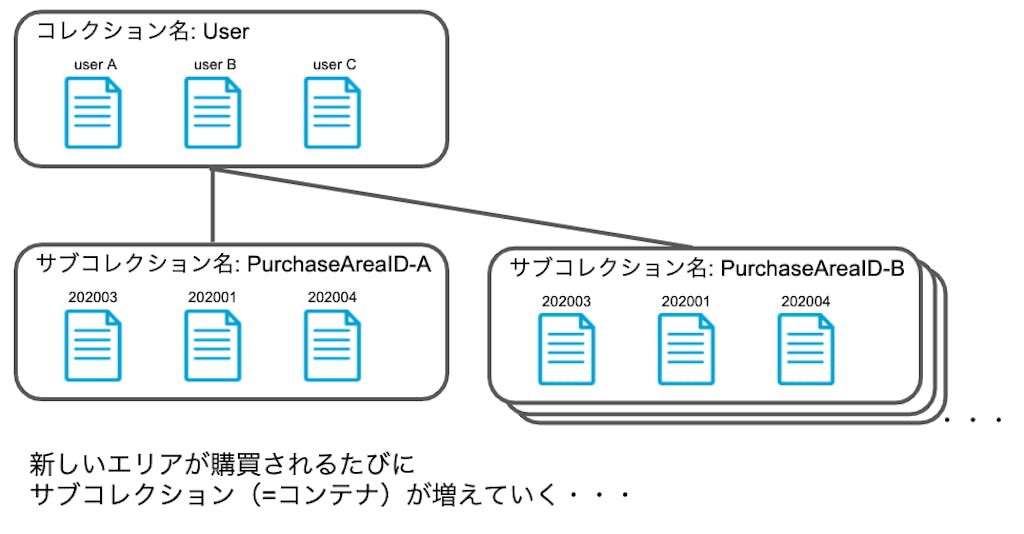
一度データモデルを定義したら、増加していくオブジェクトはドキュメントであり、コレクションはそのドキュメントの箱に過ぎません。もしドキュメントの箱が増えていく様なデータモデルを設計していたら、そのデータモデルは一度見直すことをオススメします。(使えない訳ではないのですが。。)
今回自分がアンチパターンと書いたデータモデルが有効なケースはあるのかなと少し(無理やり)考えましたが、
- セキュリティルールを個別設定する必要がない
- コレクション名をFirestoreのSDKを使って把握する必要がない
- コレクションに持たせた意味(状態)にはフィールドが必要ない
- Firestoreの仕様的に同一階層にコレクションがたくさん増えても問題ない(もしくはアプリの仕様上増えない
上記の様な条件を全て満たすのであれば、データ構造として不便を感じることはないのかもしれません。
しかし、機能拡張が困難で柔軟性もない構造であることに変わりはないと思うので、わざわざこの構造する必要もないでしょう。
以上の点を踏まえてコレクションとドキュメントを設計すると、必然的にコレクションの値は変数でなく固定値になると思います。よって先に書いた通り、アプリケーションにおいて新しいデータモデルが増えない限り、同じコレクション階層に新しいコレクションが作成されることはありません。
以上がFirestoreのサブコレクション活用にあたって、注意しておきたいポイントです。こちらはサブコレクションを使いこなすためのポイントというよりも、せっかくサブコレクションを取り入れたのに使い始めてから破綻してしまわないためのポイント、といった感じで捉えていただければと思います。
Go Horikoshi
MLOps Div. Lead / Kaggle Master
React.jsやTypeScriptを中心としたフロントエンド技術や、機械学習・データ分析・GISなどを活用したサービス開発について発信していきます。