この記事は GiXo アドベントカレンダー の 7日目の記事です。
昨日は、Business Optimization Div. 紹介でした。
MLOps Div. の廣津です。本記事では、弊社の機械学習基盤である Refeed について、現状のアーキテクチャや技術要素について掘り下げながら紹介していきます。
Refeed の位置づけ
Refeed は弊社の社内向けの機械学習ツールとして開発しているプロダクトであり、主なターゲットは、分析コンサルティングを業務としている社内のアナリストやデータサイエンティストを想定しています。MLOps Div. の紹介記事でも書いているとおり、大規模な機械学習による実験を簡単に実行できるような環境を提供することで、社内の分析案件を効率化することを目的としています。
Refeed はあくまで分析コンサルティングを補助するためのツールなので、一般的な事業会社の機械学習基盤で重要視されるような、モデルの継続的な学習・評価や Feature Store、推論のパイプラインのような機能は今のところは不要なため提供していません(この理由から Refeed に「機械学習基盤」という表現を使うのは少し大げさに思われるかもしれませんが、ひとまずこのまま書き進めます…)。このような機械学習を簡単に実行するためのツールとしては DataRobot のようないわゆる AutoML ツールを想像される方が多いかもしれませんが、 Refeed はより弊社の分析スタイルに特化したツールであり、既製のツールではカバーできないことも要望ベースで追加開発していけるという、自社開発ならではのメリットもあります。
“Refeed” という名前は、機械学習の結果から得た示唆を次の仮説に繋げて試行を繰り返していくというフィードバックのループを何度も回すことに由来しています。データから機械学習をもとに最初の仮説を得るまでの労力を限りなくゼロに近づけていくという意味で、「初期仮説ゼロ化ツール」とも社内では呼ばれています。
Refeed のアーキテクチャ
前置きが長くなりましたが、 Refeed の設計について紹介していきます。早速ですが、現状のアーキテクチャの概略は以下のようになっています。
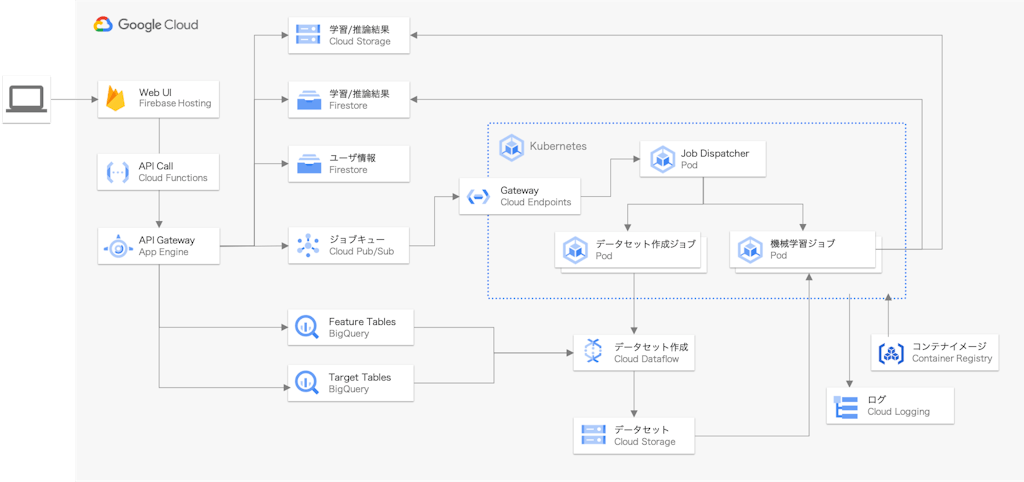
ユーザは Web UI 上からデータセットの作成や機械学習の実行、および結果の閲覧が可能です。ユーザごとに閲覧できるプロジェクトを制限することで、社内でも閲覧が限定されるような秘匿性の高い案件やデータであっても安全に使用できるような設計としています。
ジョブのスケジューリングと実行は全て Kubernetes 上で行っており、様々なデータセット形式や機械学習モデルに対応するため、抽象化した k8s のジョブクラスを定義することで拡張性を高めた設計となっています。機械学習のモデルと実験のパイプラインはモデルごとに Docker イメージとして Container Registry に保存し、用途に合わせて利用できるようにしています。提供する機械学習モデルの選定やパイプライン設計については、私をはじめとした社内の kaggler 達のコンペ経験が活かされている部分もありそうかなと(勝手に)思っています。
また、要素技術については MLOps Div. の紹介でも記載したとおりですが、GKE クラスタを始めとする各種インフラは全て Terraform で管理し、Argo CD や kustomize、conftest などを使用して全てコードとして管理を行っています。
次節以降で、以下の各機能の設計についてより細かく紹介していきます。
- 機械学習の並列実行
- データセット作成
- 実験管理
- 実験結果の可視化
機械学習の並列実行
弊社の分析のケースとして、巨大なデータセット1つに対して1つの機械学習モデルを作成するのではなく、データセットをより細かい単位(社内ではパーティションと呼んでいます)に分割したうえでモデルを作成して、各種評価指標の他、モデル間で特徴量の重要度 (feature importance) や部分依存 (partial dependence) 、 SHAP などを比較していくことが往々にしてあります(もちろん、学習に十分なだけのデータ量がある前提です)。パーティションの分割例としては、「部品ごと」や「人の属性ごと」といった形です。このような実験方法を取る場合、1回の実験で数百や数千の機械学習モデルを作成することも珍しくはありません。そこで、機械学習を並列に効率よく実行するための仕組みが必要でした。
機械学習(モデルの作成)というワークロードの特性上、定常的にリソースを確保・使用し続けるのではなく、一時的に大量のリソースを使用して終わったらリソースを解放という動きが運用コスト的にも望ましいです。これを実現する手段として、 Refeed では Kubernetes の Job を使用しています。予め定義した各機械学習モデル・データセットサイズに適切な GKE のノードプール(場合によってはノード自動プロビジョニング)にジョブを割り当てることで、このような動きが簡単に実現できます。GKE のノードプールの活用については以前の記事でも少し触れているので、興味がある方はご覧いただければと思います。
ジョブの実行管理には、当初は Cloud Composer (Airflow) を使っていましたが、ワークロードに応じた動作中のクラスタの拡張・縮小ができない、運用コストが高い、度々 Airflow 起因のエラーに悩まされる、などなどの理由もあって利用を中止しました。Flyte や Argo Workflows などの k8s と親和性の高いワークフローエンジンを採用する案もありましたが、現状ではそれらを必要とするほどの複雑な処理がそもそも存在しないため、自作の job dispatcher と k8s のジョブ管理機能で概ねやりたいことは実現できています。
下の画像はある日の Refeed の GKE クラスタのリソース使用状況を撮ったものですが、これだけのリソースを使用する規模の実験を何の事前準備もなく回せるのは Kubernetes あってこそだと思います。コスト面においても、 preemptible インスタンスを使用できるメリットが非常に大きいです。

余談として、機械学習を簡単に実行するための手段としては BigQuery ML も選択肢の一つに挙げられるかと思います。弊社でも一部のモデルを BigQuery ML に置き換えることも検討はしましたが、実行コストがネックとなり今の所導入には至っていません。
データセット作成
順番が前後しましたが、機械学習を並列実行するためには、各パーティションのデータセットを事前に作成しておく必要があります。弊社では BigQuery を社内の標準のデータ基盤として使用しているため、機械学習のためのデータセットとなる特徴量や目的変数のデータも、利用者に事前に BigQuery のテーブルとして作成してもらう方式を取っています。この時、パーティションを分割するためのキーとなる列を1列作っておいてもらうことで、データセット作成とモデルの学習をそのキーごとに分割して実行することで並列化を実現しています。
データセットの作成には Dataflow を使っており、データセット作成用の k8s ジョブ内で Dataflow ジョブをキックして実行しています。以下の図のように、パーティション分割用に指定された列でデータを分割した後、それぞれを CSV として GCS に保存しています。
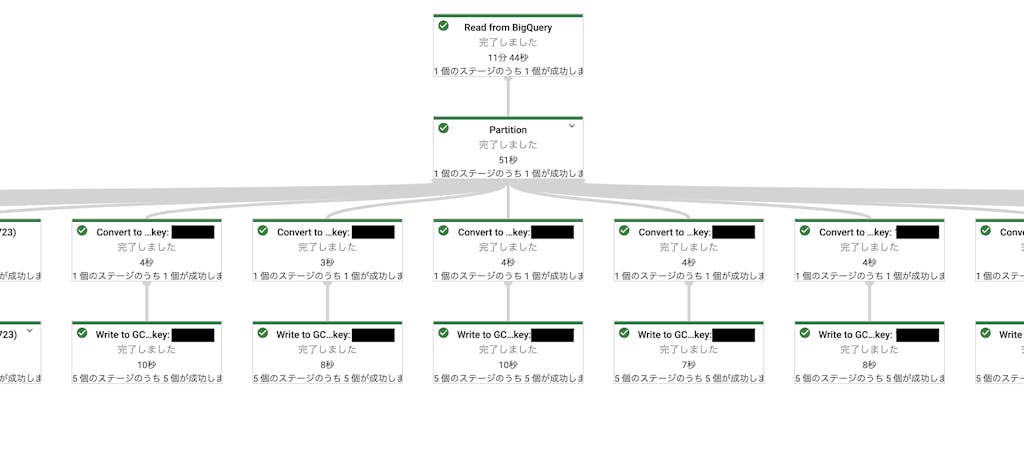
Dataflow の使い所としては、以前の機械学習基盤における Cloud Dataflow の活用という記事でも紹介していますが、TFDV も挙げられます。小規模のデータであれば pandas-profiling や Sweetviz のようなツールでデータを俯瞰することができますが、弊社の分析案件で対象とするデータは数 TB に及ぶ場合もあるため、それらのツールは選択肢になり得ません。もちろん、 BigQuery を使って色々なクエリを叩くことで等価な処理を実現することは可能ですが、労力をかけずに統一的なフォーマットでデータの統計情報を取得でき、 Firestore などに結果を連携できるのは非常に有用だと思っています。
実験管理
Refeed のプロトタイプを作った初期はちょうど MLflow の ver. 1.0 が出たころ(2019年12月ごろ)だったので、実験管理には当時最も筋が良さそうな MLflow を使用していました。しかし、 MLflow の UI では前述のような大量のモデルの横比較は対応できず、可視化できる項目も限られていた(現在はかなり改善されてきていると思いますが)ということもあって、内製の Web UI と Firestore を使った管理に落ち着きました。現在はデータセットの作成や実験の実行といった機能も全てこの UI 上で完結するようになっているので、結果としては内製に踏み切って正解だったと思っています。
実験管理のアプリケーションも今では選択肢が豊富にありますが、実際のユースケースに合わせて選定するのが最も重要だと思います。場合によっては、弊社のように自作してしまうのも1つの手段として検討してみてもいいかもしれません。
実験結果の可視化
実験結果を確認するための手段としては、社内標準の BI ツールである Tableau が用いられることがほとんどです。Tableau での可視化のために、Refeed の実験結果は全て規定のフォーマットの CSV ファイルとして GCS に保存し、インポートするだけで簡単に結果を確認できるようにしています。複数の分析案件で実験結果の保存フォーマットや可視化のためのデータ加工方法がバラバラになってしまう、というのも受諾分析の問題として起こりがちですが、Refeed を使うことでフォーマットが標準化されるというのも導入による一つのメリットかもしれません。Tableau を使った可視化については本アドベントカレンダーで後日公開される予定なので、そちらをご参照ください。
もちろん、Refeed の Web UI としても可視化機能は準備しているので、 UI 上での可視化を想定して Firestore にも同様に実験結果を格納する設計となっています。フロントエンドは私の担当ではないので、ここでは詳細は割愛します。
おわりに
本記事では、弊社の機械学習基盤である Refeed について紹介しました。Refeed やトチカチ(後日こちらもアーキテクチャを紹介予定)などのインフラ・バックエンドは私一人で全て設計から開発・運用までを担当しているということもあって、まだまだ改善したくても手が回っていないところが多々あるのが現状です。とはいえ、技術的な課題がたくさんある中でそれを一つ一つ解決していくのは非常にやりがいもあるので、来年も引き続き頑張っていきたいなと思います(?)
明日は MLOps Div. Lead の堀越より、「SPA の First View 表示速度を改善する」を公開予定です。
Masaaki Hirotsu
MLOps Div. 所属 / Kaggle Master
機械学習・データ分析基盤の構築に関わる事例や、クラウドを活用したアーキテクチャについて発信していきます