
この記事は GiXo アドベントカレンダー の 14 日目の記事です。
昨日は、すごいぞ Dataform でした。
MLOps Div. の廣津です。本記事では、弊社が提供しているサービスであるトチカチについて、裏側でどのような技術が使われているのかを紹介していきたいと思います。先日私がアドベントカレンダーの記事として公開した、 MLOps Div. の紹介記事 や 機械学習基盤 “Refeed” のアーキテクチャという記事を先にご覧いただけると、本記事の内容がより理解しやすいかもしれません。
トチカチの開発については Google Cloud の顧客事例としても紹介していただいていますが、このインタビュー記事の公開後に機能の追加や設計の変更も多数あったので、本記事では2020年12月現在の情報について書いていきたいと思います。
トチカチが提供する機能
トチカチでは、ユーザが指定した4次メッシュ(500m四方)ごとに様々なデータをレポートとして提供しています。以下の画像は、実際にトチカチで弊社ビル付近のいくつかのエリア(4次メッシュ)を指定したものです。左上の9桁の数字が4次メッシュコードに当たります。
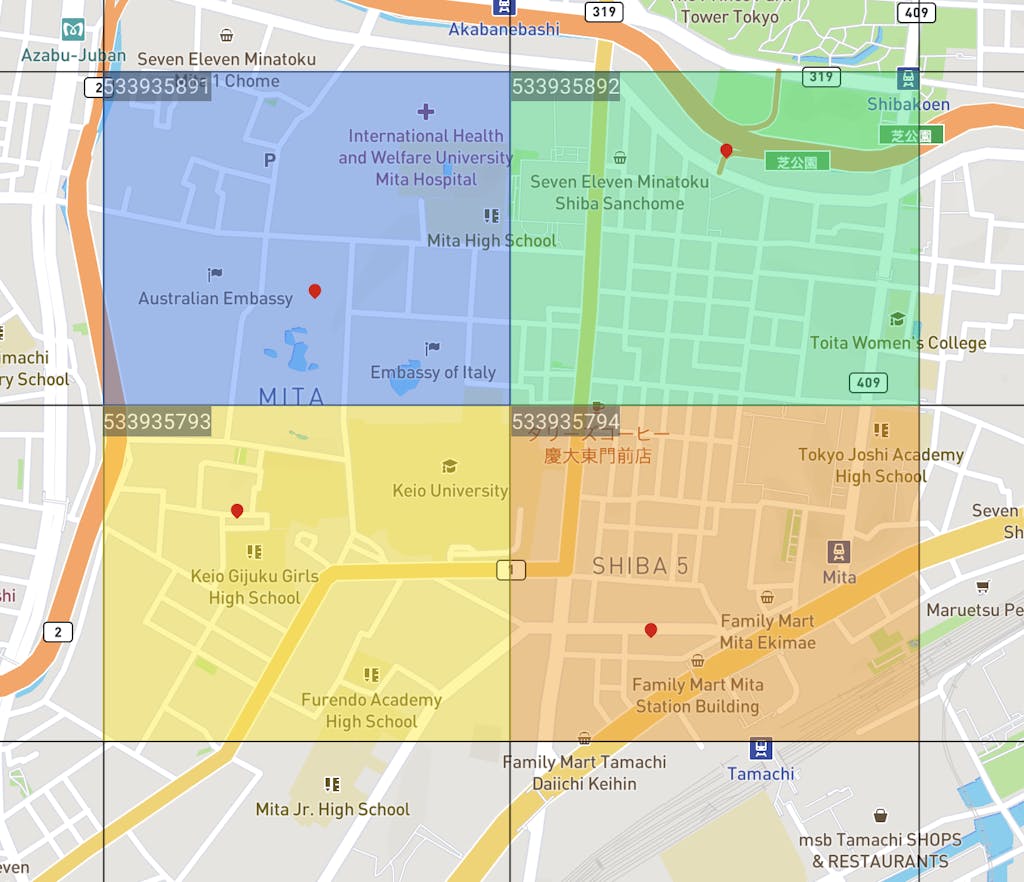
トチカチで現在レポートとして提供している主要な情報としては、以下のようなものが挙げられます。
- 人口データ(総計、性年代別、居住地別)や天候などの過去推移
- リアルタイムな人口の推移
- パラレルワールドにおける人口の予測値(コロナウィルスがなかった場合における人口を機械学習モデルによって予測した値)
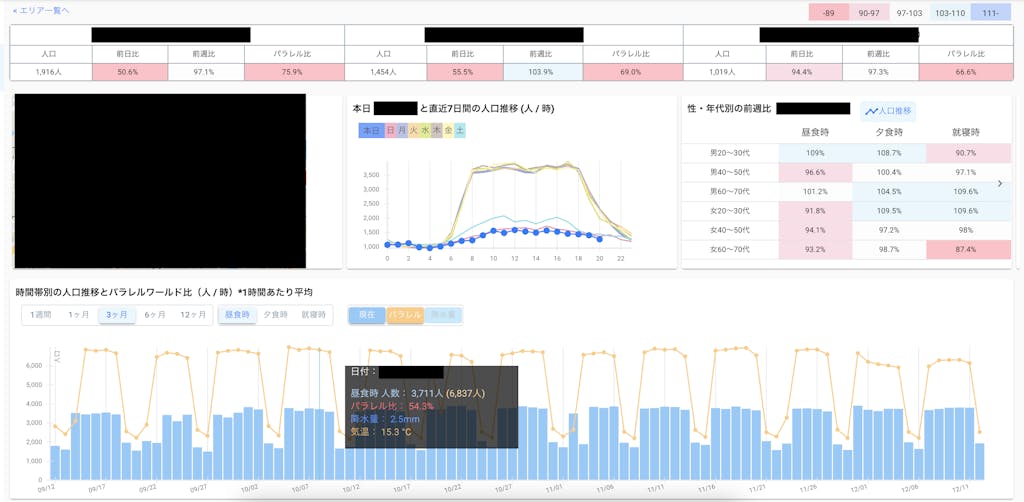
このようなデータを4次メッシュという非常に細かい領域に対して提供するためには、裏側では単純に4次メッシュの数だけ元となるデータが必要となり、膨大なデータを管理しなければならないことがお分かりいただけるかと思います。また、リアルタイムな人口データを提供するために、データが増え続けることも考慮しておく必要があります。(Refeed の記事にも書いたとおり、私一人でトチカチ含め他のプロダクトの開発もやりつつこの管理を行う必要があるという点も重要ですが…)
データの提供に際しても、4次メッシュごとに様々なデータの加工処理を行うだけでなく、パラレルワールドの予測値を提供するための機械学習モデリングも必要です。特に機械学習モデリングについては、4次メッシュ単位でモデルを作成して推論処理を行うことになるため、事前にモデルを作成しようとすると、それだけで膨大なマシンリソースやコストが要求されてしまいます。
これらの問題に対処するため、実際にトチカチではどのような設計を行っているのか具体的に紹介していきます。
トチカチにおけるデータモデリング
トチカチのデータモデリングについて詳細を説明する前に、まずはアーキテクチャの全体像を見ておきたいと思います。GKE 周りの設計は Refeed とほぼ同じなので、興味のある方はこちらをご覧ください。
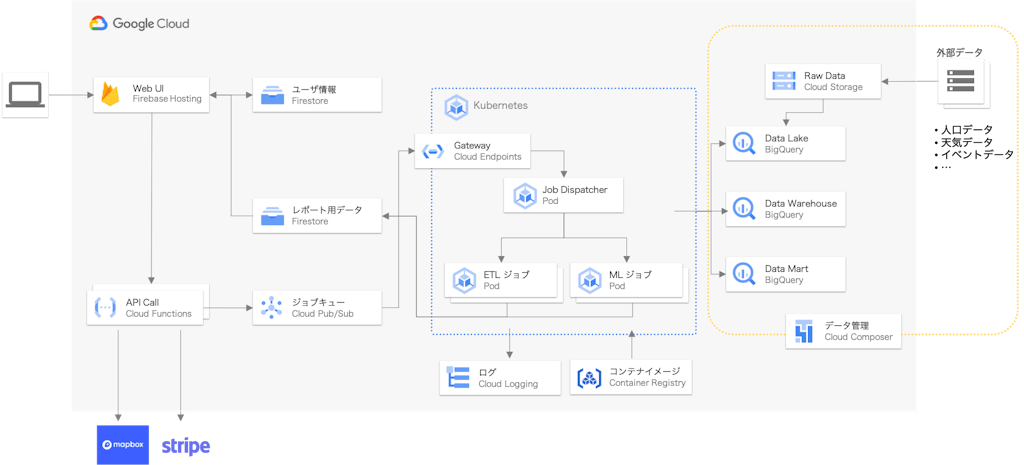
トチカチでは、 Web UI で表示するためのデータは Firestore 、外部から取得している生データやそれらを加工したデータは BigQuery に保存しています。
データレイク・データウェアハウス・データマートの3層を BigQuery のデータセットとして管理する方法はこちらの記事などで提唱されているものですが、BigQuery の低コストで大規模なデータを処理できる恩恵を最大限に享受しながら、データを一元管理し、 SQL によって統一的なデータの加工処理を記述できるということに大きなメリットがあります。
BigQuery の活用
BigQuery を採用した大きな理由の1つとして、データがどこまで増えるか分からない場合にも対応でき、データが増え続けても運用負荷はほとんど変わらないという点が挙げられます。トチカチで使用している各種外部データの取得はサービスが継続する限りは続ける必要がありますし、データの種類が今後さらに増えていく可能性もあります。このような事前のデータ量の見積もりが立てられない場合であっても、後述するデータのパイプラインさえしっかり整備されていれば、運用はほぼ気にする必要がありません。
逆説的に言えば、 BigQuery を活用したサービス設計を行う上で注意すべき点は、データセット・テーブルの設計やコスト面にあると言えます。簡単な例を見ながら、この点について深堀りしていきましょう。例えば、ある4次メッシュコードに対して日付ごとの人口を確認したいという場合、以下のような SQL を実行することが考えられます。
|
1 2 3 4 5 6 7 8 9 |
SELECT meshcode, date, population, FROM `dataset_xxx.table_xxx` WHERE meshcode = 533935892 ; |
テーブルサイズが小さい場合は特に気にする必要はありませんが、トチカチで扱う人口データは TB のオーダーであるため、適切に設計されていないテーブルに対してこのようなクエリを叩きまくっていると運用コストが高すぎてサービスが成り立たなくなってしまいます。
このようなケースに対しては、 BigQuery のテーブルパーティショニング機能を事前に設定しておくことが必要です。4次メッシュコードは9桁の整数であるため、整数範囲パーティションで分割したテーブルを作成することによって、1クエリ当たりのコストを大幅に削減することができます。トチカチのレポート用に整備しているテーブルは多岐に渡るため、それぞれについてパーティショニングやクラスタリングの設計を適切に行うことが(基本的ですが)重要になってきます。
データ管理
トチカチで提供しているデータは全て外部から取得しているデータを元にしているため、データソースに応じてデータ取得から BigQuery へのインポートまでのパイプラインを整備する必要があります。また、リアルタイムに更新されていく人口データを反映していくための処理も必要です。
このような複雑なデータの管理を実現するために、トチカチではワークフローエンジンとして Cloud Composer (Airflow) を採用しています。ワークフローエンジンは他にも色々選択肢がありますが、 Airflow を採用するメリットとしては、以下が挙げられると思います。
- リッチな GUI
- DAG 単位で処理フローを管理できる
- スケジュール実行が容易
- S3 や GCS、 BigQuery などさまざまなデータソースに対応できる
- 複雑な処理も Python で記述できる
以下の画像は実際に運用している DAG の一部を切り取ったものですが、データソースごとに DAG を作成しスケジュール設定を行うことで、柔軟なデータのインポートや加工処理が実現できます。

余談ですが、直近では Dataform が Google Cloud 傘下に入って無料で使えるようになったことで、これまで Cloud Composer (Airflow) や Cloud Workflows などを必要としていたような複数の SQL のパイプライン処理やスケジュール実行も非常に簡単に管理できるようになりました。トチカチにはまだ導入できていないですが、今後データパイプラインを設計していく上では非常に有力な選択肢になると考えています。
トチカチにおける機械学習モデリング
冒頭にも触れたとおり、4次メッシュそれぞれに対して機械学習モデルを作成する場合、必要なモデル数は数万や数十万といった単位になります。さらに、モデルの精度改善のために特徴量の追加やパラメータの変更も行っていく必要があるため、毎回これだけの数のモデリングを行うのは現実的ではありません。加えて、トチカチのサービス形態上、1人も購買していないエリア(4次メッシュ)も日本全国を探せば多数存在するため、それらに対してモデルを更新しつづけていくのも無駄なコストとなってしまいます。
幸いなこととして、現状のトチカチのサービス設計上、購買から数秒で結果を返さないとユーザを待たせてしまう、というようなケースは発生しないため、機械学習による結果を取得して表示するまでに多少の猶予があります(今後のサービスとしてどうなるかはまた別の話ですが、本記事ではサービス仕様の話については省略します)。
以上の要件から、トチカチでは購買が行われたエリアに対して都度機械学習モデルを作成して推論を行う、という処理方式を採用しています。大まかな流れとしては以下のようになります。
- 購買処理が完了
- Firebase Cloud Functions 経由で機械学習ジョブをキック
- GKE で Job を実行
- BigQuery からデータを取得
- 学習
- 推論
- Firestore へデータを格納
- ユーザが Web UI から結果を確認可能になる
1つのエリアに対して購買から Firestore へのデータ格納まで概ね1〜2分程度必要となりますが、 Kubernetes を活用することで、ワークロードに最適なリソースを割り当てつつ並列処理を可能にしています。Kubernetes ジョブの処理については Refeed のものとほぼ同じなので、本記事では割愛します。
サービス開始当初は機械学習用の計算リソースとしてマネージドの Cloud Run を利用していましたが、推論だけでなく学習も行う必要がある都合上、並列数や利用できるリソースの上限が厳しいということもあり、 GKE に置き換えるに至りました。 Cloud Run の方が運用は圧倒的に楽なので、サービス特性に合わせた選択が必要だと思います。
おわりに
本記事では、トチカチを支えるデータモデリングや機械学習モデリングの設計について紹介しました。大規模なデータを扱うサービスを少人数で設計・運用していく事例の1つとして参考になれば幸いです。
明日は Design & Science Div. の松田より、「Tableau の LOD 表現で注意すべきこと」を公開予定です。
Masaaki Hirotsu
MLOps Div. 所属 / Kaggle Master
機械学習・データ分析基盤の構築に関わる事例や、クラウドを活用したアーキテクチャについて発信していきます









