
この記事は GiXo アドベントカレンダー の 18 日目の記事です。
昨日は、クラウドデータ基盤をTerraformを使ってIaC化 & 量産する でした。
MLOps Div. の濱田です。
近年、機械学習は目覚ましい発展を遂げており、それに伴って複雑なモデルを解釈する方法も多く提案されています。今回はその中から、弊社でも活用している SHAP に焦点を当てていきます。
SHAP とは
SHapley Additive exPlanations の略称です。モデルがその値を予測する理由について、ゲーム理論の観点から説明を試みるアプローチです。つまり、ゲーム内で複数のプレイヤーが協力して獲得した利得を貢献度に応じて公正に分配する考え方を用いて、複数の説明変数が相互に影響しあって予測に与えた影響度を算出します。
利用するデータ
sklearn でも提供されているオープンデータの The Boston house-price data を利用します。
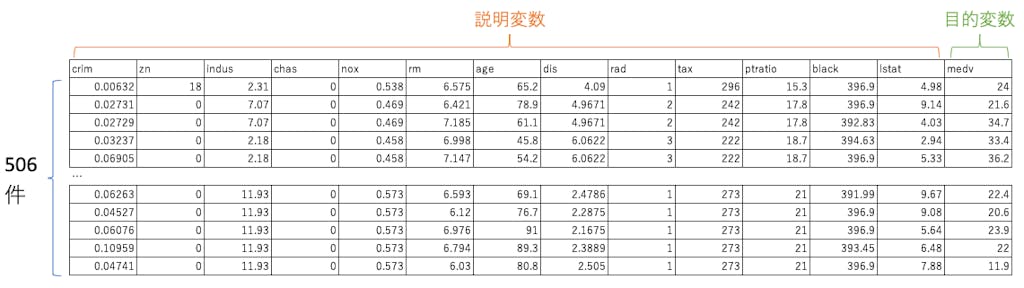
データの中身は上記のようになっており、13 の説明変数と 1 つの目的変数から成る、506 件のデータセットです。目的変数は medv で、特定の地域の住宅価格(単位は 1000 ドル)の中央値です。
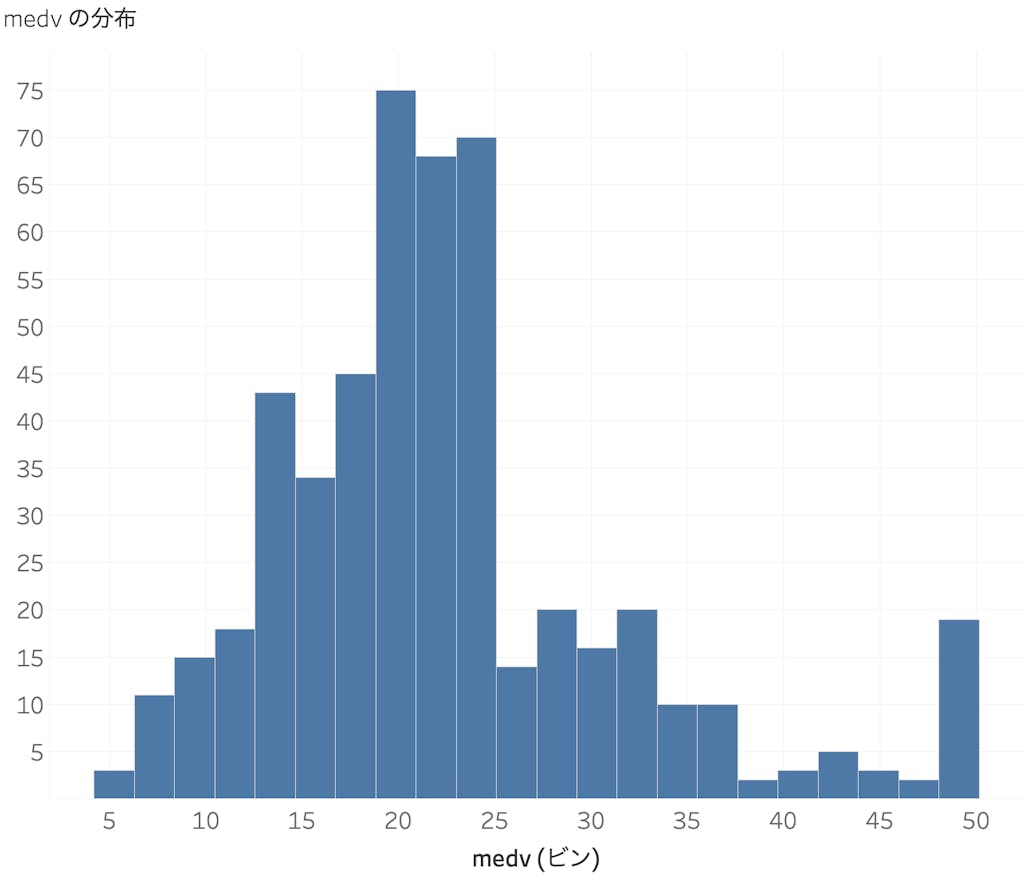
なお、medv の分布は下記のようになっています。
SHAP の算出方法
数式は割愛します。Python で実装する場合、shap がメジャーなライブラリです。また、LightGBM であれば学習済みモデルの Booster.predict の引数に pred_contrib=True を指定することで、SHAP が得られます(こちらを参照)。得られた結果は下記のような 2 次元配列になっています。

上の画像には先頭の五行が記載されています。
各行の一番右にある「23.404」という値は SHAP のベースラインで、共通した値となっています。
これに列名を付与してデータフレームにすると、下記のようになります。

データフレームの値を行方向に足し合わせると、予測値が得られます。つまり、ベースラインの値に対して、それぞれの説明変数がどれだけプラスに、あるいはマイナスに働いたことで、予測値が得られたかを説明することができます。
一行目については、住宅価格を予測するうえで rm が最もマイナス(-1.46)に、lstat が最もプラス(4.42)に働いて、予測値 27.551 が得られたことを示しています。
Tableau による可視化
弊社では可視化に Tableau を利用する機会が多いため、今回もそちらを利用して可視化を行っていきます。
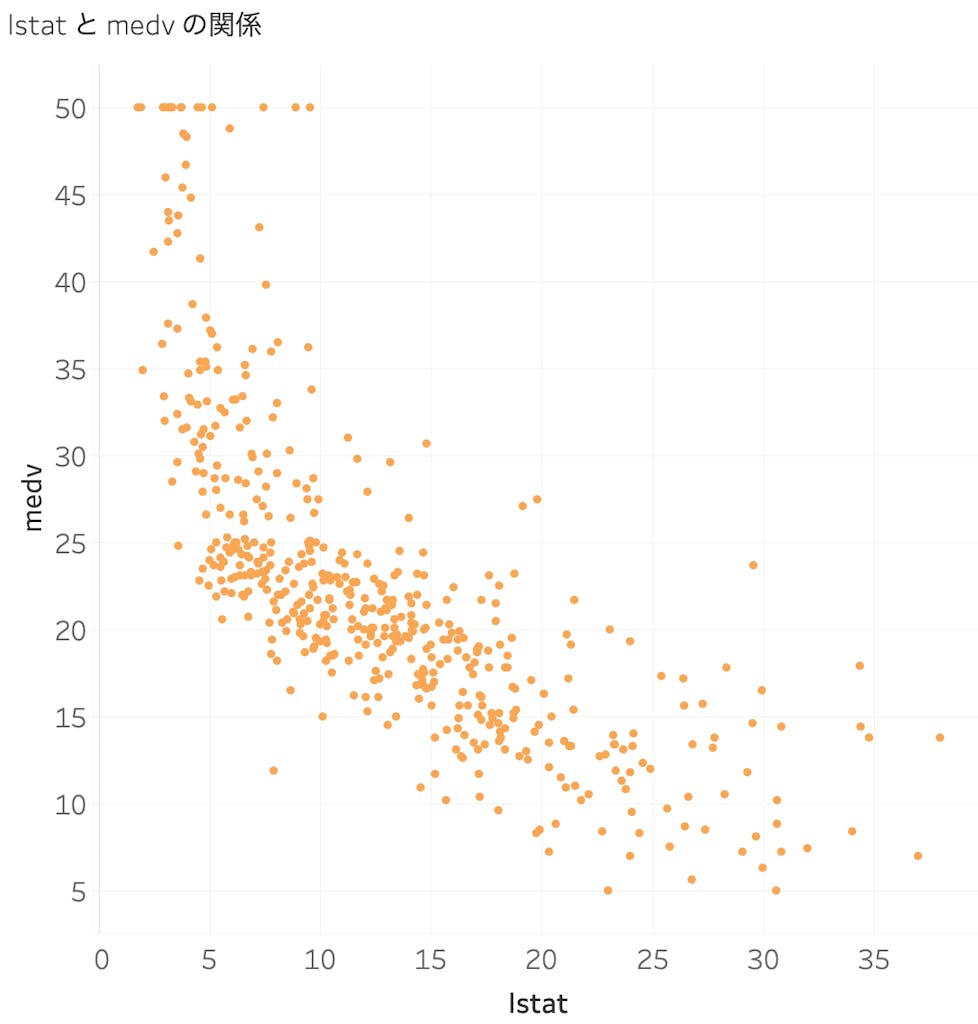
今回は、予測に与える影響が大きい lstat(低所得者の人口に占める比率)に焦点を当てて説明していきます。
SHAP の前に、そもそも lstat と medv の関係を可視化してみると、下記のようになります。低所得者の比率が増えるほど、住宅価格が下がる傾向にあるようです。
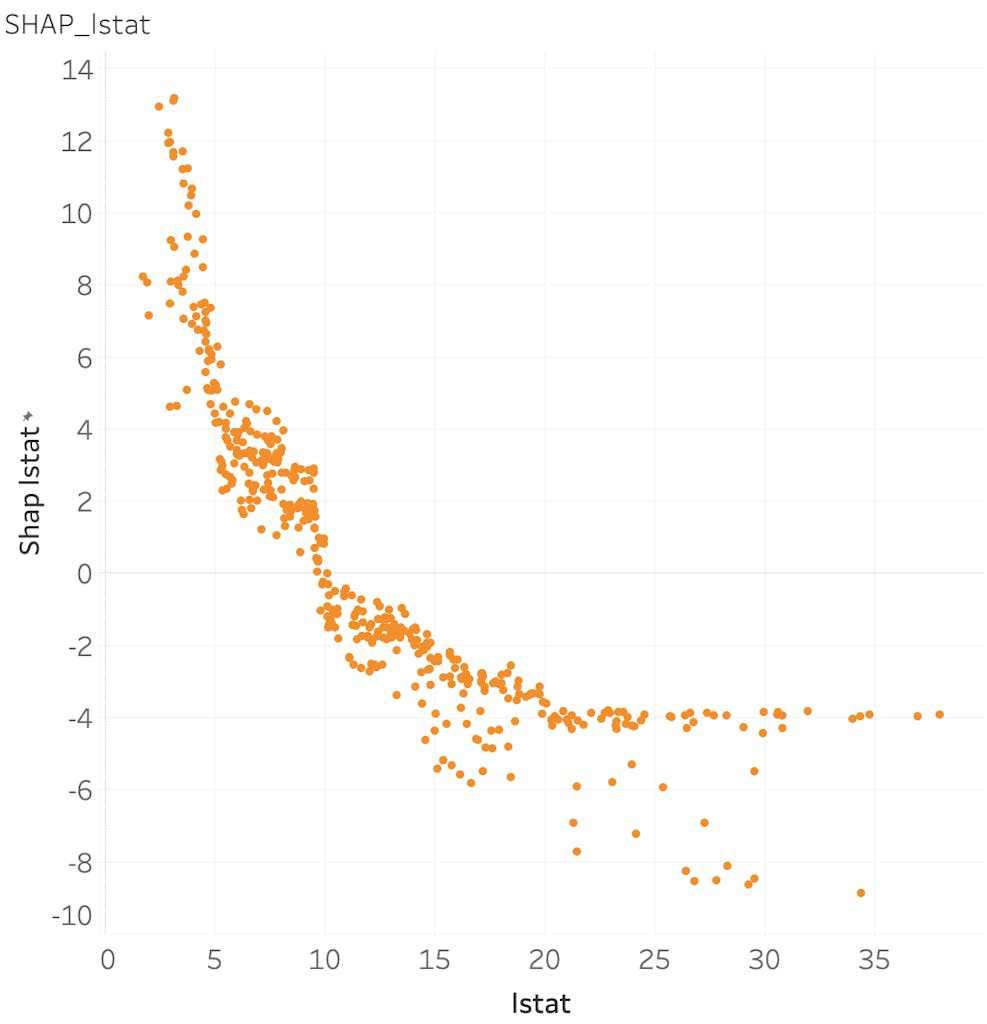
次に、lstat の SHAP を可視化すると下記のようになります。lstat が 10 までは 住宅価格に対してプラスの影響を与えますが、それを超えるとマイナスに作用することが読み取れます。ただし、20 を超えると、マイナスの影響も頭打ちになっているようです。
ここで 1 つ実験をしてみます。下記のように lstat に小さな noise を与えた列を追加して同様に SHAP を算出すると、どのような結果が得られるでしょうか。
|
1 2 3 |
import numpy as np dataset["lstat_noise"] = dataset["lstat"] + np.random.normal(0, 0.1, len(dataset)) |
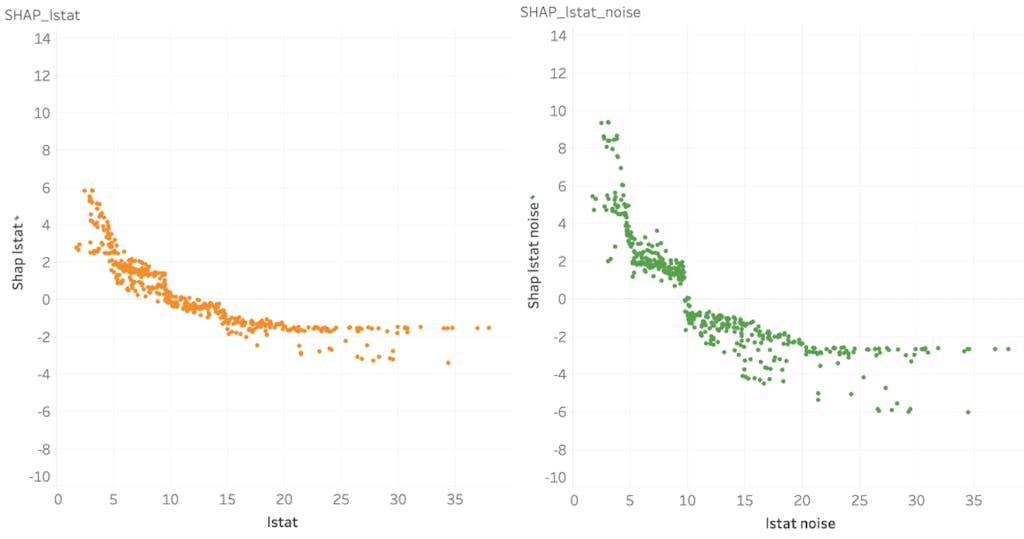
左が lstat 、右が lstat_noise の SHAP です。noise を加える前の lstat の SHAP を、ちょうど分け合うような結果になっています。これは極端な例ですが、強く相関する 2 変数をモデリングに利用して SHAP を見る際は、状況に応じて変数を選択することで解釈しやすくなる場合があります。
「機械学習を解釈する」という考え方
一口に「解釈する」といっても、その目的は様々です。
例えば、私が RTX 3090 を購入するため銀行でローンを申請したにもかかわらず、機械学習により完済の可能性が低いと判断されたため、申請を却下されてしまったとします。SHAP に基づいて銀行側から説明された却下理由は、「クレジットカードの所持枚数が多く、過去にリボ払いを滞納した経験があり、年齢が若いため」でした。しかし私はこう考えます。「理由の説明はもういいから、どうすれば申請が通るようになるかを教えてほしい」と。かといって「年齢が若いので 5 年後に出直してください」といわれても困る(急がないとコンペが終わってしまう)ので、努力したら何とかできる範囲で申請が通るシナリオを教えてほしいというのが、私の目的です。このような反実仮想サンプルを効率良く収集するためには、SHAP によるアプローチは適していません。例えば Diverse Counterfactual Explanations (DiCE) のようなアプローチをとることになります。
ここで挙げた他にも、Interpretable Machine Learning*1 に、機械学習の解釈について豊富な知見がまとめられています。SHAP や 反実仮想についても記載されているので、ぜひ目を通してみてください。
おわりに
機械学習を解釈する方法の中で、特に SHAP に焦点を当てて説明してきました。SHAP は機械学習を解釈するうえで、有効な手段の一つです。Explainable AI は今後も発展していく分野と思われるので、引き続き動向をチェックしていきたいです。
なお、私が所属する MLOps Div. では Refeed という社内向け機械学習ツールを開発しており、SHAP や 部分依存 (partial dependence) の出力を一定のフォーマットで簡単に得ることができるようになっています。MLOps Div. の紹介記事はこちらです。興味を持っていただけた方は、是非目を通してみてください。
さらに、私達と一緒に働きたい!と思っていただけた方がいらっしゃれば、ぜひこちらからご応募ください。まずはカジュアル面談で話だけ聞いてみたい、という方も歓迎です。
明日は Design & Science Div. の遠藤より、「Design & Science Div. 紹介」を公開予定です。
*1 Molnar, Christoph. “Interpretable machine learning. A Guide for Making Black Box Models Explainable”, 2019.
Shota Hamada (濱田 翔大)
MLOps Div. 所属
Kaggle 、将棋、コーヒー。React + TypeScript によるフロントエンドの開発を担当しています。









