
Amazon Redshift Spectrum によってデータ分析の業務フローが変わる
先日、サンフランシスコで開催された AWS Summit 2017(2017.4.18 – 19)で Amazon Redshift(以下、Redshift) の新機能な発表がありました。Redshift は、データウェアハウス 用のデータベースとして大量データを素早く、そして通常のデータベースと変わらない感覚で使えることから、2012年11月のリリースから多くの企業で使われてきました。そして、ここ2年ほどは大規模なアップデートはなく、成熟したサービスでは?っと思ってました。今回発表された Amazon Redshift Spectrum は、その沈黙を破り新たな領域へ踏み出す革新的な機能です。今回は技術的な詳細情報を省き、Redshift Spectrum を導入することで分析業務の何が分かるかを簡潔に説明したいと思います。
従来の Redshift による外部データインポートについて
Amazon Redshift Spectrum (以下、Redshift Spectrum) は外部データを Redshift で使うための機能です。通常、データベースで外部データを使用する場合は「インポート処理」を行う必要があり、Redshift にもインポート処理を行うための「COPYコマンド」があります。まず、Redshift Spectrum の内容に入る前の事前知識として、従来行われてきた Redshift のインポート処理についてご紹介します。
通常のデータベースでは、扱えるデータはデータベースの中に登録されたデータに限定されます。そのためには、CSVやXML、JSONなどの様々な形式のデータファイルをデータベースに登録できる形に整形し、専用のインポート命令でデータベースに登録する必要があります。
これらの作業はETL処理と言われ、データ整形のための特殊スキルが必要になったり、データベース自体にもデータを登録するための膨大なデータ領域と登録処理のためのCPUやメモリなどのリソースを必要とします。そのため、データウェアハウスであるRedshiftであっても、テラバイトクラスのデータを取込むためには場合には、それなりの準備が必要になっていました。
新しい Redshift Spectrum による外部データ参照について
Redshift からクラウドストレージのデータファイルを参照するだけ
従来の方法では Redshift による外部データファイルを取込必要があったのに対し、Redshift Spectrum は外部データファイルを取込まずにデータ参照のみを行います。
取込む対象のデータファイルは、AWSのクラウドストレージの Amazon S3 (以下、S3) に保存します。Redshift 側では 「外部スキーマ」と呼ばれるデータ領域を作成し、そこに S3 上のデータファイルのレイアウトに合わせた「外部テーブル」を作成することによって、あたかも Redshift 上のテーブルのように S3 上のデータファイルを参照することができます。また、取扱い可能なデータファイル形式としては、CSVやTSVなどの区切り文字があるデータフォーマット、Parquet、SequenceFile、RCFileといったデータ処理用に編集したデータフォーマットが使えるようです。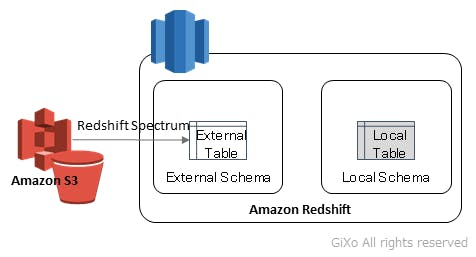
Redshift Spectrum のインターフェースは3種類
Redshift Spectrum に外部テーブルには以下の3種類のインターフェースがあります。
- Redshift に直接外部テーブルを定義
- Amazon Athena の外部テーブルを参照
- Amazon EMR などのHiveメタストアを参照
この様にAWSの別サービスで構築したデータ定義を参照することで、Redshift Spectrum で2重で外部テーブル定義を作成せず、開発資産を有効に活用することができます。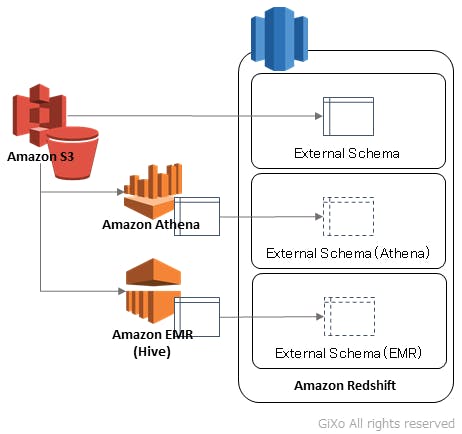
Redshift とは独立したプロセスで処理
Redshift Spectrum を使用した場合、Redshift のディスク容量を使用しないため、大容量のデータファイルを Redshift の空きディスク容量を気にせず使用することができます。更に Redshift Spectrum は Redshift 本体とは独立したプロセスで処理されるため、Redshift 本体に全く負担をかけることなくデータ参照することができます。また、自動的に並列処理などを行ってくれるため、巨大なデータファイル参照も高速に処理してくれます。
抽出方法は通常のSQL命令
外部テーブルと言っても、通常のテーブルと違うところはデータ更新ができないくらいです。そのため、外部データを作成したら、必要な時に、必要なデータだけSQL命令で参照することができます。また、Redshift 内の実テーブルとのテーブル結合も可能ですので、データ分析者は外部テーブル、実テーブルを意識せず使用することができます。
Redshift Spectrum と Amazon Athena のベストプラクティス
Redshift Spectrum を使用し、直接 Redshift に外部テーブルを作成する方法では、JSONなどの非構造化データデータを扱うことはできません。これではデータレイクとは言えません。そこで、Amazon Athena (以下、Athena) と合わせて Redshift Spectrum を使用します。
Athena はCSVやTSVなどの区切り文字形式の構造化データ以外にJSONなどの非構造化データフォーマットも取り扱うことが可能です。また、Athena 自体にチューニング機能がありますので、Redshift Spectrum 単体より様々なデータフォーマットをより高速に処理することができます。
(参考:Amazon Athena の分析サービスとしての位置付けについて考えてみる)
しかし、ここで問題が1点あります。それは、Athena を使用した場合、データ参照する度にAWSサービス使用料金($5/TB)が掛かってしまう事です。 1度だけのデータ参照だけで用件が済めば問題ないですが、データ分析の試行錯誤で何度も問い合わせた場合、参照する元のデータファイルが大きければ無視できない金額になります。
そのため、データ分析で深掘りするデータ範囲が決まったら、SQL命令の「INSERT + SELECT」などでデータ絞って、Redshift 内の実テーブルに登録してから試行錯誤のステップに入ることをお勧めします。そうすることによって、Athena の使用料金が発生しなくなるため、安心して試行錯誤のデータ分析をすることができます。(Athena のテーブルのデータ型はSTRING型などの独自の形式ではなく、VARCHAR型などのDBのデータ型に合わせる必要あり)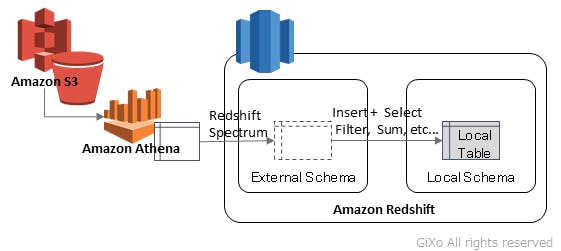
2018.03.09 UPDATE
Redshift Spectrum はAthenaの機能を使わずにJSON形式のファイル読込に対応しました。
https://aws.amazon.com/about-aws/whats-new/2018/03/amazon-redshift-spectrum-now-supports-scalar-json-and-ion-data-types/
Redshift Spectrum のこれからの課題
現在、Redshift Spectrum と Athena が使えるAWSリージョン(サーバー設置場所)は、米国に限定されています。そのため、既存のデータ分析環境が東京リージョンにある日本企業はシステム構成を変える必要があり、すぐの導入は難しいと思います。また、金融関係の企業では国外にデータを保存するために多くの手続きが必要になる場合があり現実的ではありません。
IoTログの活用などでデータ量が増えてきている今、Redshift Spectrum や Athena のような大量データを扱うためのデータレイク機能は、これからのデータ分析業務の中で必須の機能となることは間違いありません。これらの機能は、これから機能拡張も行われると思いますし、近い将来、東京リージョンでも使えるようになると思います。そのためにも事前調査などでいつでも導入できる体制は整えておく必要はあると思います。





