
Airflowを導入することでエンジニアは処理本体の開発に集中できる
分析業務に限らず定常的な処理はバッチ処理として纏めることは多いと思います。そして、バッチ処理も実行するタイミングが決まったら、自動化システムとしてバッチ処理をスケジューリングすることで手作業から解放されます。この様なバッチ処理をスケジューリングするものが、タスクスケジューラーと呼ばれるツールやフレームワークになります。今回は最近注目されているタスクスケジューラーの Apache Airflow(以下、Airflow)について技術的な内容は省いて、導入することで変わる開発手法についてご説明します。
バッチ処理と自動化システムの違い
Airflowの説明をする前に「手作業が入るバッチ処理」を「自動化システム」にするまで何を考え、開発する必要があるかについてご説明します。(プログラマーのあるある話です)
バッチ処理では複数のタスクを順に実行する
バッチ処理の中では1つ1つの処理の塊が「タスク」として存在し、これをエンジニアはコーディングなどによって開発しています。そして、このタスクを順に実行することで大きな処理を行うバッチ処理として機能します。例えばETL処理では、「ファイルサーバーからファイルを取得 → データ加工 → データベースにデータインポート」といった3つのタスクを順に実行する処理がバッチ処理になります。
自動化システムでは作り込みが必要
上記のバッチ処理では、バッチ起動などの手作業が残っています。そのため、深夜のバッチ起動やリアルタイムバッチ処理には問題があり、これを解消するために自動化という次の開発ステップに進みます。単純な処理や重要度の低いバッチ処理の場合は、OS標準のタスクスケジュラー(Windowsタスクスケジューラーやcronなど)でも運用に支障はありませんが、基幹業務のバッチ処理や社外に公開しているシステムなどでは、バッチ処理の障害がダイレクトに影響します。
そして、自動化システムではバッチ処理本体の「正常系の処理フロー」だけではなく、障害が発生した時の「異常系の処理フロー」を考慮する必要があります。様々な条件を考慮し「バッチ処理が確実に処理できる」ように作り込みを行う必要があり、もし、障害は発生した場合も「直ぐに障害に気付き、即座に障害復旧できる」ようにする必要があります。
システム開発では、バッチ本体の正常系の処理より、異常系の処理の方が開発・試験が重いことが多く、これらを軽減するために様々なタスクスケジューラーが登場しています。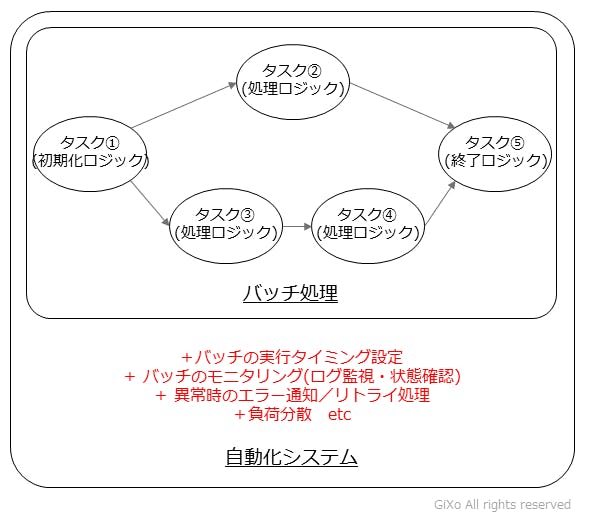
Airflowとは何者か
前置きが長くなってしまいましたが、これからAirflowのご説明をします。
AirflowはAirbnbが提供しているオープンソースのタスクスケジューリング・モニタリングのフレームワークです。現在、Webのソースコード管理サービスであるGitHubから誰でも無料で入手可能でLinux系のおOSにインストールすることができます。
Airflowの機能使用することでバッチ処理の自動化システムを構築する時の異常系の処理をフルスクラッチでコーディングする必要がなくなります。例えばタスクで障害が発生した場合のリトライ処理、メールによるエラー通知、ログの収集をAirflowの機能が肩代わりしてくれます。
Airflowはタスクとして、Linuxシェル、またはPythonプログラムで作られたファイルを実行することが可能ですが、直接、Airflowの中にコーディングすることも可能です。AirflowからLinuxシェルを実行できるため、Linuxシェルを使ってJava言語などで作られたファイルを実行することも可能です。
弊社でもタスクスケジューラーとしてJobSchedulerを3年前から使用してきましたが、今回、新規システムを導入するための複数のスケジューラーを選考した結果、その中からAirflowが最も優れている判断しました。その判断に至ったAirflowのイケているポイントについてご説明します。
依存関係のあるタスクスケジューリング
タスクを順に実行していく単純なものならバッチなら苦労はしませんが、上記のイメージのように複数のタスクを同時に実行し、それらの処理終了を待ってから次のタスクを実行するような場合、ちょっとした手間が必要です。
Airflowでは、このようなタスクの依存関係をDAG(有向非巡回グラフ)によって実現しています。タスクをDAGで定義することで、依存関係の無いタスク(前に処理するタスクが無い)が最初に実行され、順に依存関係が解消されたタスクが実行されていきます。DAGは「タスクを1個ずつ順に実行していく」ような処理フローに比べて分かりにくい気がするかもしれませんが、依存関係からタスクの実行順が決まるため、非常に合理的な実行方式だと思います。
Pythonプログラムでスケジューリングする
一昔前のタスクスケジューラーではタスクの実行順や実行タイミングを専用の設定ファイル、またはGUIベースのコンポーネントで設定することが一般的でした。この方法では少ない設定でスケジューリング設定などが行えるメリットはありますが、ツールでサポートされていないことを行おうとした場合、設定の泥沼にはまったり、実現できない事がありました。
AirflowではPythonプログラムでスケジューリングします。プログラミングすることで設定のハードルが上がった気がするかもしれませんが、Airflowのチュートリアルに掲載されているプログラムコードを多少変えるだけで殆どのシステムに対応可能だと思います。そして、設定をPythonプログラムで行うことでスケジューリングの自由度が増しています。
各種データベースやGCPの操作コンポーネントが充実
Airflowではタスクを専用のコンポーネント(Pythonファンクション)で呼び出す方式を取っています。このコンポーネントにはORACLEやMySQLなどのメジャーなデータベース、Hiveなどに対応しているため、コンポーネントに直接SQL命令を記述するだけでデータベースを操作できます。
特に下記のように Google Cloud Platform(略称、GCP)サービスのコンポーネントが充実し、 少ないコーディングで大量データのETL処理を実行できます。(実際の処理は各クラウドサービス内で実装する事もあります)
- BigQuery(分析用データウェアハウス)
- Cloud DataFlow(ストリーミング処理サービス)
- Cloud DataProc(Hadoop/Spark実行プラットフォーム)
- Cloud Storage
これらのコンポーネントは世界中の有識者によって、日々拡張されているため、これから期待できます。
モニタリングがブラウザベースで行える
ここまででAirflowを使用することでバッチ処理のスケジューリングが非常に軽減されることはご理解いただけたと思います。次はバッチ処理の管理機能についてです。
Airflowではスケジューリングされたバッチ処理をWebベースのモニタリング画面で確認できます。モニタリング画面にはタスクの実行状態、実行ログなどがグラフなどでビジュアライズされています。また、データベースの接続情報などの実行に関わる設定も行えます。そのため、スケジューリングは自由度の高いPythonプログラミング、モニタリングは見やすいブラウザベースで行えるため管理が非常に楽になると思います。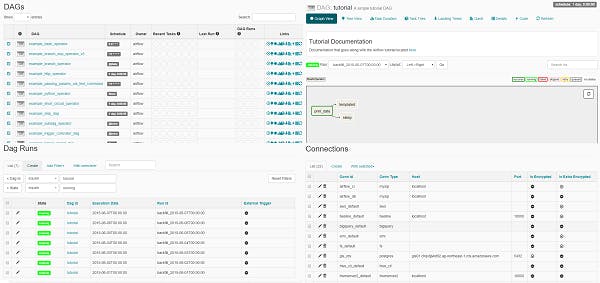
まずは使ってみよう!
このようにAirflowを使うことで複雑なバッチ処理でも比較的簡単にスケジューリングとモニタリングができる事が分かると思います。
特にETL処理などの複数のタスクを組み合わせるバッチ処理では、少ないコーディング量でタスクの依存関係から最適な順番でタスクを実行してくれるため、最初は小規模なバッチ処理でも拡張性を考えてAirflowを選択するのも良いと思います。
次回は実際にAirflowを使ってみて悩んだ事などについてお伝えできればと思います。
連載:Apache Airflow でタスクスケジューリングしてみた
- Airflowによって開発負荷が変わる(本編)
- 公式ドキュメントの読み解き方
- タスク開発のポイント
- ログを退避させる







