
LLMは万能に見え過ぎている
質問:第1回、第2回に続き、岡さんにお話を聞いていきたいと思います。
第1回はLLMが国語、システムが算数、というお話。第2回は、国語から算数への変換のお話でした。
その中で、特に「ミスしたらダメな部分は、算数でやる」ということで、AIオーケストレーターの振り分け機能もLLMでやるべきではない、とお話しいただきました。
岡:はい。「間違ってはいけないものは、LLMではやらない」、これが基本です。LLMが期待と違うアウトプットを出してくるのは構造的に仕方がないことだというお話を第1回でしました。良いとか悪いとかではなく、そういうものなんですよね。
質問:それを踏まえて、振り分け機能はPythonで書いている、ということをお聞きしましたが、今回は、その続きで、「振り分けられた先の、AIエージェント」についてお話を伺えればと思います。よろしくお願いします。
AIエージェントも、AIである必要はない!?
岡:端的に言うと、「AIエージェントも、LLMじゃなくてよい」ということになります。
質問:え!?AIエージェントなのに、AIじゃなくていいんですか?
岡:そう言い切ると、ちょっと語弊があるかもしれませんが、そもそものAIの定義をどうするか、というような話もあると思っています。
ただ、ギックスで実装するケースでは、AIオーケストレーターとAIエージェントは、共通の「Local-LLM」をBuilt-in AIとして組み込んではいますが、実体としては、Pythonでガチガチに作り込んでいます。
そのため、AIオーケストレーターのことは「Root Agent」と呼び、AIエージェントのことは「Sub Agent」と呼んでいます。Sub AgentにRAGがくっついている、という形ですね。
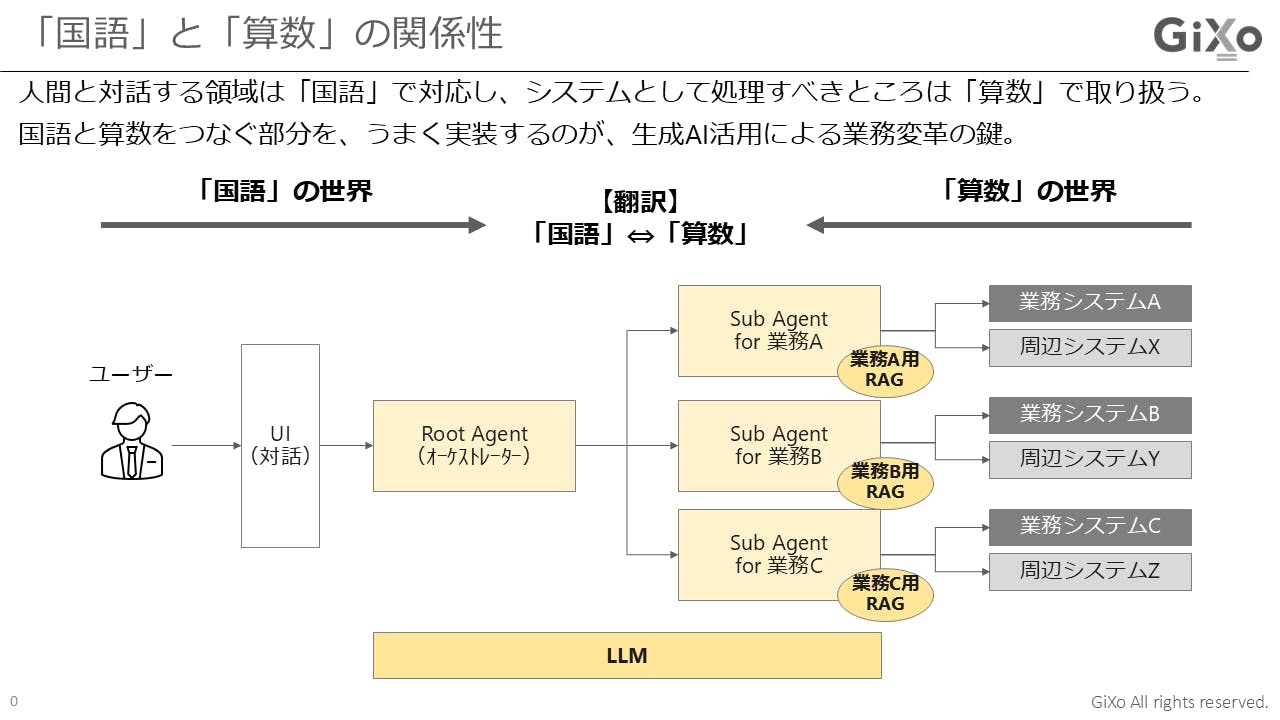
質問:どこにも「AI」って言葉がない・・・
岡:そういわれてしまうと、そうですね(笑)
もちろん、実際には、LLMを使っていますし、いわゆる生成AI技術は使っているんですよ。
ただ、それが「Artificial Inteligence(人工知能)なのか?」というと、いろんな議論はありますよね。
特に、昨今は生成AI=LLMという風に思われている節もありますから、技術的に誤解を招かないように「Root Agent」と「Sub Agent」という表現を使っています。
質問:そういう作り方で、思い通りに動くのですか?
岡:はい。むしろ、そういう作り方「だからこそ」、思い通りに動くんです。
繰り返しになりますが、LLMは国語です。Pythonで組めば算数になります。
算数の世界では、おかしな動きをしないように、制御することができます。テストして、品質を保証することができます。
算数の世界のハードル=正しくインプットを投げ込む工夫
岡:前回、国語の世界のハードルの話をしましたが、算数の世界のハードルについてもお話しておきましょう。
明日、とか、来月、という言葉をLLMはうまく処理できないという話をしました。こういう言葉に対しては、Pythonで「明日=DD+1」「来月=MM+1」という風に判定できるように記述しておけば、日付を特定可能です。これで、「来週月曜日」とかも処理できます。
こうしておけば、算数の世界で、正しい情報として取り扱うことができます。
他にも「大阪出張に行く」という場合には、「訪問先の場所」「約束の日時」「出発地点から、最寄り駅までの移動時間」などの情報を理解する必要があります。こうした情報を、適切に分解し、算数の世界で処理できる状態にしていく必要があります。
これを、LLMでの言語処理と、Pythonによるルールベースの処理によって、システムへの入力情報に変換していくことがポイントになります。
質問:なるほど。LLMの得意なところはLLMで、そうではないところはPythonで、という組み合わせによって、翻訳をしていくんですね。
岡:その通りです。また、Sub Agentは、その先の業務システムとつながっていますので、業務システムが欲しい形で情報を受け渡す使命があるわけです。
ちなみに、この「Sub Agentの先」に、LLM、いわゆる生成AIが配置されるケースもあります。
質問:どういうことですか?そこに「間違う可能性のある国語の仕組み」があるのは、大丈夫なんですか?
岡:LLMは間違う可能性がある、ということを繰り返しお話してきましたが、「そういうものだ」と理解していれば、その間違いの影響を極小化できます。要するに役割分担なんですよね。
先ほど、Root Agent と Sub Agentには、Built‐in のLocal LLMが設定されているというお話をしました。この部分に制御を組み込むことで「おかしなことは言わない」「答えてはいけないことは答えない」という設定が可能です。
ガードレールとか、そういう言い方がされますよね。それを、Root/Sub Agentで実施することを前提にすれば、その先にいるLLMが何かおかしな結果を返してきたとしても、人間に届く前に適切に処理していくことができるわけです。
質問:おもしろいですね。その他に、ポイントになることはありますか?
岡:認証・認可についても、少しだけ触れておきましょう。
その人には、どこまで見えていていいの?を管理する
岡:この話も詳しく話すと長くなるので、ほんとうに薄~い話としてお話しますが、システムを正常に運用していく際には、認証と認可というものが重要になってきます。
認証は「その人が、何者であるか」という本人確認です。
認可は「その人が、何をして良いか」という権限の強さです。
質問:一般的に、いろいろなサービスを使う際にログインしたりしますが、そういうお話ですか?
岡:その通りです。ここでのポイントは「Root/Sub Agentの先にある業務システムには、複雑な権限設定が存在している」という点です。
たとえば、人事システムの情報を、誰でも見られてしまうというのは問題ですよね。
あるいは、お店の予約情報にアクセスする際に、自分以外のお客さんの予約情報が見えてしまうのもマズいです。
そうした情報に「アクセスできない」ことが極めて重要です。そうした設定は、絶対にミスしてはいけない算数の世界ですから、LLMで処理せず、Pythonでコントロールしていくことになります。
質問:RAGのお話と似ていますね。適切なRAGにアクセスするように、振り分けるというお話。
岡:まさにそれです。今日イチ冴えてますね(笑)
RAGも、認証・認可の対象であるべきなんです。それはつまり、Root Agentが「誰との対話においては、どのSub Agentを使ってよいのか」を認識する必要があるんです。
こうしたことを、しっかりと管理しなければ、安全な仕組みとして運用することができません。
完全に算数の世界でしょう?
質問:ほんとうですね。
生成AIを業務改善に使う、というお話だと「LLMに丸投げすれば、良い感じにやってくれる」ということだと思ってしまいがちなのですが、実際には、「ちゃんと信頼性のある仕組みにしようとすると、算数の世界に踏み込まざるを得ない」ということが、よく分かりました。
今回は、初級編的な位置づけのインタビューということで、あまり詳しくない私がお聞きしたわけですが、非常に面白いお話だったので、花谷COOと岡さんの対談などで、もっと詳細な内容をお聞きして行ってみたいなと思います。
本日は、誠にありがとうございました。
岡:はい。ありがとうございます。この領域は、文字通り日進月歩、いや、秒進分歩ですから、目が離せませんよね。
LLMの次に、LAM、つまり、Large Action Modelということで、適切な言葉を探すのではなく、適切なアクションを導き出すというものも来ています。こうなってくると、自律性の高い処理が実現されますから、より一層「できること」が増えてきますよね。
私自身も、日々勉強しなければいけないなと思って取り組んでいますので、新たな知識を加えた情報発信も積極的にやっていきたいと思います。今後もよろしくお願いしますね。








