
Google BigQueryをAmazon Redshift、Microsoft Azure SQL Data Warehouseと比較
世の中にコンピュータが登場したから多くの種類のデータベース(DB)が登場し、使用用途、データ特性などで様々なDBを使い分けてきました。そして、最近ではDBの動作環境が、目の前のコンピュータではなく、クライドに移行し、更に処理できるデータ量が大きくなっています。特にビッグデータの分野では、Amazon Redshiftに代表される専用DBサービスが登場し、速く、安く、そして簡単にビッグデータの分析が行えるようになりました。今回は、そのようなクラウドのビッグデータ処理サービスの中から「Google BigQuery」について触れてみたいと思います。
Google BigQueryについて
Microsoftの場合は「Azure」、Amazonの場合は「Amazon Web Services(通称、AWS)」のように各社クラウドサービスを行っており、Googleも「Google Cloud Platform」と呼ばれるクラウドサービスを行っています。その中のビッグデータ処理サービスとして「Google BigQuery(以下、BigQuery)」があります。
BigQueryは、Azure SQL Data Warehouse(以下、Azure SQL DW)やAmazon Redshift(以下、Redshift)のビッグデータ向けDBと同様に、登録された大量データからSQLに近い命令文でデータ取得・検索・集計・結合などが行えます。また、TableauなどのBIツール、Talendなどのバッチ作成ツールなどと簡単に連携可能のため、今後のビッグデータ処理サービスとして注目されています。
今回は、BigQueryの導入方法などの実践的な内容ではなく、Azure SQL DWやRedshiftなどの競合サービスとの違い値ついて、「処理速度」「価格」「構造」の面で比較したいと思います。
Google BigQueryは「速い」
ビッグデータの分析で重視されるのが、大量データをいかに高速に処理できるかです。早速、Redshiftと処理速度を比較しました。今回検証した内容は「売上トランザクションデータ(2.5億件)と 商品マスタ(37万件)をテーブル結合(外部結合)して、別のテーブルに登録する」処理です。
- BigQuery:2m 38s
- Redshift(ds2.xlarge x 2):6m 05s
結果、BigQueryは2.5億件のデータ処理を行うのに約2分半で行うことができました。この他に検索や集計の処理を行いましたが、全ての処理でBigQueryの方がRedshiftより速く処理できました。もちろん、Redshiftの処理エンジンであるノードを増やしたり(ds2.xlargeを倍の4個に増やすなど)、sortkey(インデックスのようなもの)やdistley(データの分散キー)を設定することで、BigQueryより速くなる可能性は十分ありますが、何もチューニングしていない状態でBigQueryがこれだけのレスポンスが出ることは驚異的な事です。
BigQueryのレスポンスが早い理由として、ビッグデータ専用に作られている事にあります。従来型のDBはデータをレコード(行)単位で保存するのが一般的です。この従来型のDBの保存形式を多くの保存領域に分散させ、データ入出力を速くしたのがAzure SQL DWです。逆にRedshiftはレコード単位の保存ではなく、カラム(列)単位で保存することでデータ参照範囲を絞り、かつデータ圧縮できるため大量データを効率的に検索・取得できるようになっています。
そして、BigQueryはカラム単位の保存形式に加え、ツリーアーキテクチャと呼ばれる分散並列処理を使用しています。ツリーアーキテクチャでは、1つのSQL命令に対して、複数の処理に分解し、これを同時に実行する事で全体の処理速度を上げています。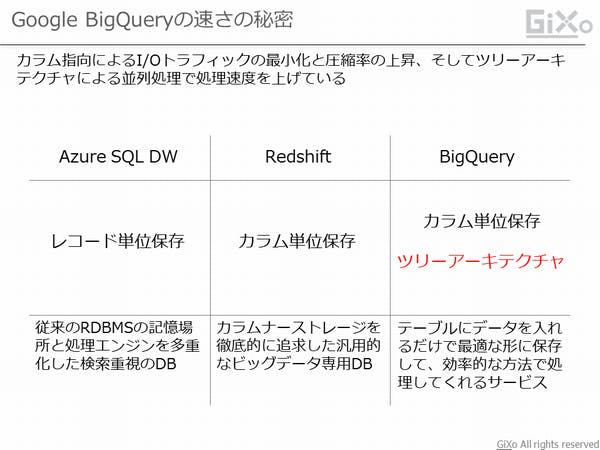
Google BigQueryは「安い」
BigQueryがどんなに優れていても、利用料金が高ければ導入することが困難になります。クラウドサービスの特徴の1つとして価格の安さがあり、自前でパソコンを購入して同様の環境を構築するよりも、圧倒的に安価格で高品質なクラウドサービスを利用できます。そのため、BigQueryも例に漏れず、非常に安い利用料金でサービスを利用できます。
BigQueryの料金体系の特徴として、時間課金が無料に近い事です。通常、クラウドサービスを使用した場合、そのサービスに見合った課金が発生します。例えば1TBデータを登録した場合、下記のような月額課金が発生します。
- BigQuery:$20.0/月
- Azure SQL DW(400DWU):$2,942.4/月
- Redshift(ds2.xlarge x 2):$856.8/月
この様にサービスにデータを保存しているだけなら、BigQueryが他のビッグデータ処理サービスより安い事が分かります。
しかし、BigQueryは時間課金が少ない代わりにスキャンデータ量による課金が発生します。BigQueryはデータ検索などの処理ごとに1TB当たり$5の料金が発生します。例えば、1時間に1回、1TBのデータに対して集計処理を行った場合、$3,600/月の課金が発生します。そのため、BigQueryは「データを随時蓄積して、月に数回だけデータ処理するような運用」に最適だが、リアルタイム分析には料金の面で不適切になります。
Google BigQueryは「シンプル」
ビッグデータDBの運用にとって、DBのチューニングは必須の作業です。レスポンスを早くすためには、どのようなテーブル構成が良いか? データの分散保存方法は? データ保存領域は十分か? インデックスはどこに張るのが最適か? など考えることは多くあります。これらの悩みはクラウドサービスになっても残っており、日々、変わっていくデータ量、分析要件などに合わせていく必要があります。しかし、BigQueryは、DBの概念に捕らわれない構造によって、非常にシンプルになっています。
BigQueryのテーブル定義で一番の特徴はデータ型の少なさです。通常、DBで文字列のデータ型を指定する場合、データ型をCHAR、VARCHAR、NVARCHARなどから選択し、格納するデータサイズを指定する必要がありました。しかし、BigQueryは「STRING」と指定するだけです。これでどんな長い文字列でも格納することができます。また、DBのテーブルのチューニングポイントであるインデックスや分散キー、データ圧縮形式などを指定する必要がなく、プログラミング言語の変数宣言をしている感覚でテーブル定義が行えます。
BigQueryは、このシンプルなテーブル定義だけで最適な形でデータを保存してくれます。これでデータ量が増えたり、予期しない長い文字列のデータが入ってきてもメンテナンスが必要ありません。
Google BigQueryは全く違う思想のビッグデータ処理サービス
このようにBigQueryは、ビッグデータ処理に特化した「構造」「料金体系」になっています。データ保存方法や処理方式について、従来のDBの概念ではない、新しい方法を取り入れています。また、料金面でも他サービスと差別化を図るため、バッチ処理に特化した料金体系になっています。
ただ、ビッグデータに特化した半面、失われたものもあります。BigQueryは「ビッグデータ処理サービス」ですが「ビッグデータ処理DB」とは言い切れません。現在、BigQueryでは「INSERT(追加)」や「UPDATE(変更)」、「DELETE(削除)」のSQL命令を使うことができません。これらを操作を行うためには、Webコンソール画面から操作するか、API命令を実行するなどの独特な操作が必要になります。
【2018.01.24 UPDATE】
BigQueryのアップデートによってSQL命令で追加、変更、削除ができる事を確認しました。(詳しくは下記参照)
BigQueryの標準SQL対応によって競合サービスからの乗り換えが発生するか? ~Redshiftと使用感を比較してみた~
これは、Azure SQL DWは「SQL Server V12」、BigQueryは「PostgreSQL 8.0.2」のようにベースとなるSQL命令があるのに対して、BigQueryはSQL命令の「SELECT(検索)」でデータ問合せができるだけでベースとなるSQL命令が存在しないためです。そのため、SQL命令を主体として使用する分析者にとって、作業面で若干のハードルになる事は間違いありません。
これらのメリット/デメリットを見極め、BigQueryの使い所を探していく必要がありそうです。







