
分析の試行錯誤フェーズではRedshift。分析の”型”が決まったらBigQuery。
ビッグデータ分析においてデータベースは必要不可欠であることは言うまでもありません。これらのビックデータ向けデータベースの代表格としてオンプレミスではOracle Exadata、クラウドサービスではAmazon Redshift(以下、Redshift)などがあります。弊社でもRedshiftを長年使用してきましたが、最近、Google Cloud Platform(以下、GCP)のBigQueryが、色々改善されたため、RedshiftなどのRDB(リレーショナルデータベース)と使用感を比較してみました。
前回までのBigQueryのおさらい:速い・安い・シンプル
実は1年半前の2016年6月にBigQueryについての調査結果をブログに紹介させて頂きました。これについて、簡単に要点だけご説明します。(参考:BigQueryは「速い・安い・シンプル」の3拍子揃ったビッグデータ処理サービス)
BigQueryは速い
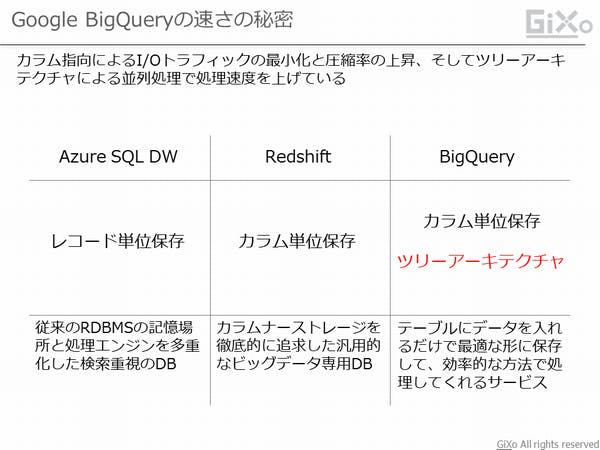
BigQueryはSQL命令を解析して、複数の処理に分割して並列処理してくれるため非常に高速に処理してくれます。Redshiftのノードのような処理グレードはなく、処理の重さによってBigQueryが自動的にスケールアウトしてくれるため、データ量が多くなって高速に処理が行えます。
BigQueryは安い
Redshiftなどのクラウドデータベースでは、データベースサーバーとしてサービスが起動しているため、起動しているだけで課金が発生してしまいます。しかし、BigQueryはデータベースサーバーのように常に起動しているサービスではありません。クエリーが実行されるごとに処理エンジンをスケールアウトしてくれるため、ただデータを保存してるだけなら非常に安く運用できます。(1GBあたり$0.02/月)
ただ、BigQueryのクエリー実行時の参照先のデータ量によって課金($5/TB)が発生します。そのため、プログラムなどで頻繁に大量データを参照する場合は注意が必要です。
BigQueryはシンプル
RedshiftなどのRDBではテーブルにデータ型を決めてデータを格納します。データを厳密に保存する用途としては非常に大切なのですが、文字列情報のデータ型の場合、データ型と一緒にバイト数を決める必要があり、バイト数以上のデータを登録しようとするとエラーが発生します。しかし、BigQueryでは文字列のデータ型は「STRING」の1つだけです。バイト数も指定する必要ありません。そのため、テーブルにデータを登録する時にはデータのバイト数を気にせずテーブルにデータを追加することができます。
また、BigQueryはパフォーマンスチューニングや空き容量を気にする必要はありません。通常、RedshiftなどのRDBでは、テーブルにインデックスやソートキー、データの保存場所の指定などのパフォーマンスチューニングが必須です。しかし、BigQueryはそれらのパフォーマンスチューニングの必要はなく、データベースの容量上限もないため、データ量が増えるたびにメンテナンスする必要はありません。
BigQueryで標準SQLが使えるようになった
BigQueryではデータ参照を行う時にSQL命令を使用します。2016年より前までは独自仕様のSQL命令だったため、データ参照(SELECT)しかできず、サポート外のSQL関数が多かったり、SQL構造も独特なものが多く、決して使いやすいものではなかったです。しかし、2016年中旬ごろから標準SQLをサポートし始め、現在では挿入(INSERT)、更新(UPDATE)、削除(DELETE)が行えるようになり、基本的なSQL関数やWindow関数が使え、一般的なRDBと遜色がないSQL命令での操作が行えるようになりました。
上記のブログを書いた当時は、標準SQLを対応し始めたころで、使っていて「あれ? 使えないぞ?」と思うSQL関数や書き方があったり、問合せ結果をテーブルに追加する(INSERT ~ SELECT)が使えなかったりしていましたが、現在は問題ありません。テーブル挿入の時に登録先のテーブルの項目を省略した書き方ができないなどがあり、煩わしさは感じますが慣れてしまえば作業に影響が出るものではありません。
BigQueryの標準SQL対応は、データ分析者にとってSQL命令だけでデータ参照・挿入・更新・削除できる事は非常に重要なアップデートです。なぜなら、今まで使い慣れたSQL命令だけ作業が行えることで、RDBと同じ感覚でデータ分析が行えるからです。
RDBユーザーがBigQueryを使う時に注意すべきポイント
BigQueryの標準SQLサポートが進んだことで非常に使いやすくなりました。しかし、BigQueryはデータベースではありません。そのため、RDBと勝手が違うところが多々あります。
CREATE TABLE文が使えない
RDBではテーブルを新規作成する場合、SQL命令のCREATE TABLE文を実行することが一般的です。SQL命令とて実行できることでテーブル挿入や削除と同じ感覚、実行環境から操作をできます。しかし、BigQueryはCREATE TABLE文をサポートしていません。BigQueryのテーブルを新規作成する場合はGCP管理コンソール、コマンドライン(CLI)、APIなどからBigQuery独自の命令を実行する必要があり、テーブル新規作成を頻繁に行う分析作業の場合は操作が非常に面倒です。
2018.02.23 UPDATE
ベータ版ですが、BigQueryでCREATE TABLE文が使えるようになりました。データ型はBigQueryのString型などを使うことになりますが、普通のデータベースの感覚でCREATE TABLE文が書けます。
https://cloud.google.com/bigquery/docs/data-definition-language
バックアップという考えがない
RDBにはトランザクション処理機能があります。この機能を使うことでデータ更新結果を確認してコミット(処理の確定)を行ったり、複数のSQL命令実行時の整合性を取ったりできます。しかし、BigQueryにはトランザクション処理機能はありません。そのため、1度実行したSQL命令は処理が即座に確定してしまい、ロールバック(処理の取消)はできません。
通常のRDBの場合は、SQL命令のコミット後もデータベースのスナップショットやログなどからデータ復旧は可能ですが、BigQueryにはスナップショットなどはありません。そのため、BigQueryの変更処理は絶対に取り消せません。
データ分析作業は手作業によるSQL命令実行が多いため操作ミスが発生しやすいです。そのため、定期的にテーブルの複製を作ったり、テーブルデータをテキストファイルとしてダンプするなどの独自バックアップ対策は必要です。
テーブル単位のアクセス権限が設定できない
RDBの場合、1つのデータベースを複数人がそれぞれの用途で使用できるようにテーブル単位でのアクセス権限(読み取り/書込みなど)を設定することができます。しかし、BigQueryはテーブル単位でアクセス権限の設定はできません。BigQueryはデータセット(RDBのスキーマのようなテーブルの集まり)単位でアクセス権限の設定をする事しかできません。そのため、アクセス権を意識してテーブルを作成するデータセットを決める必要があります。
BigQueryへの接続方法が特殊
現在、BigQueryのODBC/JDBCドライバは標準SQL未対応のベータ版しか存在しません。(2016年末からベータのままのため正式サポートされるか微妙)そのため、今まで使い慣れたSQL実行ツールやBIツールではBigQueryに対応できない事があります。
BigQueryをプログラムやSQL実行ツールで接続がAPI経由になる場合、通常のDB開通と異なるGCP側の設定に躓くかもしれません。また、APIからBigQueryを操作する場合はリスエスト数上限(100個/秒)に気を付けた方が良いと思います。プログラムなどで連続的に処理を実行する場合は結構引っ掛かりやすいです。
Redshiftの分析資産をBigQueryに移行することで性能改善とコスト削減が行える
ご紹介した内容以外にBigQueryには、カラム追加やデーブル複製、文字列検索が速いことなどRDBと比較してメリットも多いです。しかし、SQL命令などの操作面でデータ分析者に負担がかかる可能性はあります。特に分析の試行錯誤でCREATE TABLE文を頻繁に実行する場合、分析者はSQL命令以外の技術スキルや別の実行環境からの命令実行が必要になるためストレスを感じる可能性はあります。
そのため、Redshiftなどの使い慣れたビッグデータ用のデータベースで分析の試行錯誤を行い、定常的に分析する内容が決まり「システム化」に進む場合はBigQueryに乗り換えれば良いと思います。BigQueryが標準SQLに対応したことでRDBからのシステム移行のハードルは低くなっているはずです。また、「システム化」することでテーブル更新ミスなどのオペレーションミスのリスクは非常に小さくなっているはずです。






