
RDSの機能を使えばRedshiftのデータを使用したGIS環境も構築できる
クラウド上のデータベース(クラウドデータベース)は、非常に高性能、かつ安定していながら、費用的や技術的にも容易に環境構築することが可能です。しかし、これらの利点の代償として”柔軟性”を失ってしまっています。1つ目は”場所”の柔軟性を失い、常にインターネットから接続できる環境からでないと利用できません。2つ目は”拡張性”の柔軟性です。今回はこのクラウドデータベースの”拡張性”の柔軟性を補完し、コストダウンする方法についてAWSを例にご説明します。
Redshiftは完全なPostgreSQL互換ではない
Amazon Redshift(以下、Redshift) は PostgreSQL 8.0.2 をベースに作られています。そのため、PostgreSQLで実行できるSQL命令などの開発資産はRedshiftでも転用可能なため、大規模データの分析データベースの中核として使用されてきました。しかし、分析性能を上げるためにベースのPostgreSQLから以下のような性能・機能を捨てました。
- SQL命令による登録/更新が遅い(オーバーヘッドも掛かる)
- テーブルの一意キー/外部キーなどの制約がない
- 使用できないPostgreSQL関数・機能がある
- PostgreSQLの拡張機能が追加できない
1番や2番のような機能は、業務システムやECサイトのような「大量アクセスに対して瞬時に応答し、確実に登録」するような用途では不向きですが、Redshiftは大量データ分析処理に限定しているため問題になりません。(Redshiftをそのような用途で使ってはいけません) また、3番の関数や機能(トリガーやシーケンスなど)はプログラミングで代用可能です。しかし、拡張機能についてはGIS機能や全文検索機能などがあり、プログラミングで代用するには限界があります。
Redshiftの足りない機能は他のサービスで補えばよい
Redshiftは大量データ分析に特化したサービスですが、他にもデータの質や処理要件などによって多くの種類のクラウドサービスが提供されています。そして、AWSでもデータベースのように使えるクラウドサービスとして以下の3つがあります。(実際には10個以上サービスがありますが今回の用途で絞っています)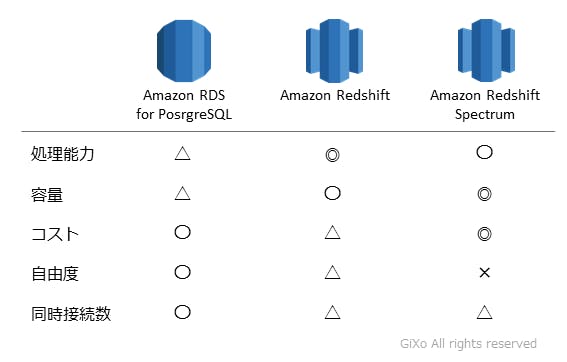
初めにAmazon RDSですが、これはオンプレミスのORACLEやSQL Server、MySQLやPostgreSQLなどをそのままクラウドサービスとして提供しているクラウドデータベースです。フルマネージドで安定したデータベース環境を容易に構築でき、性能や記憶容量のアップグレードが行えます。また、オンプレミス程ではありませんが、データベース拡張機能をサポート範囲内で追加できるため、それなりの自由度はあります。今回はAmazon RDS for PostgreSQL(以下、RDS)を使用した説明に絞らせて頂きます。
次にRedshiftですが、先ほど説明したように拡張機能追加は不可能で自由度はRDSよりありません。また、大量データを処理できますが、大量データを保存するための容量を確保するためには、Redshift拡張(スケールアウト)する必要があり、それによって使用時間による従量課金が増えてしまいます。
最後にAmazon Redshift Spectrum(以下、Spectrum)ですが、このサービスは上記2つのサービスと異なり、Redshiftのサブ機能として存在しています。Spectrum自体はデータ参照は可能でもデータ追加・更新・削除は行えません。しかし、Spectrumはクラウドストレージ(Amazon S3)に保存された大量のテキストファイルを高速にデータ検索・参照することが可能です。そして、S3のデータ保存料は非常に安いためデータレイクとして使用できます。
各クラウドサービスで得意な事を作業分担する
上記で説明したRDS、Redshift、Spectrumは用途の異なるサービスですが、共通機能している機能としてSQL命令によるデータ参照が可能なことです。つまり、バラバラの3つのサービスを繋げれば、SQLだけで下記のような効率的、かつ自由度が高いデータ分析が可能になります。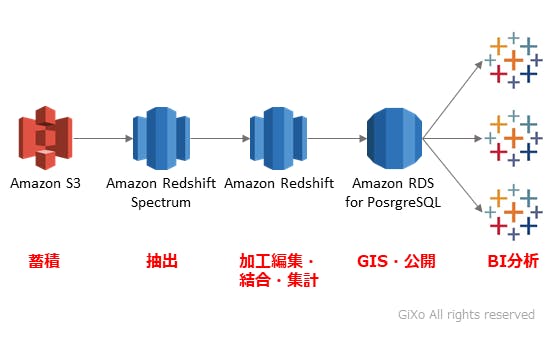
まず、クラウドストレージであるS3にデータを集めます。この時「データ分析で使えるか?」などと考えてはいけません。今は使わないデータでも、今後使う可能性があるかもしれません。データは資産ですので、ある程度フォルダ分けやファイル名を統一してデータ蓄積します。(詳しくは:クラウドストレージの賢い管理方法)
次に必要なデータをS3からSpectrum経由でRedshiftに必要なデータをコピーします。Spectrumは参照先のデータファイルサイズによって課金されます。1度の抽出だけで要件が完了すれば問題ありませんが、何度もデータ参照する場合はRedshift内にコピーした方がコスト面で安心です。(不要になったらRedshiftから消せばいいです)
Redshiftでデータ結合・集計などの加工処理を行った後にRDSにデータを渡す方法ですが、DBリンク(dblink)という方法を使用します。DBリンクはPostgreSQLの拡張機能になり、RDSに追加できます。RedshiftもRDSから見ればPostgreSQLとして扱われるため、RDSの外部参照テーブルからRedshiftの実テーブルを参照可能です。また、RDSにはGIS(地理情報システム)による分析が可能なPostGISも追加できるため、位置情報による分析などが大量データから行うことも可能です。
そして、BIツールで使用可能なほどに小さくなったデータをRDSにコピーしていれば、Redshiftへのデータ参照が必要なくなります。その結果、月次のデータ分析用途なら使わない期間にRedshiftを停止(正確にはバックアップ取って削除)可能になるため、Redshiftの稼働コストを削減できます。
足りない機能を補うサービスは同一クラウドである必要はない
今回はAWS内のサービスに完結した例を出しましたが、特にAWS内で納める必要もないと思っています。
例えばS3とSpectrumが実現していたデータレイクについては、JSON形式のデータに限定すれば Azure Cosmos DB の方が高速かもしれません。また、機械学習機能を追加するのであれば Google Cloud Machine Learning Engine の方が安く、高速に処理できるかもしれません。もし、これらのマネージド型のクラウドサービスで対応できないのであれば、仮想マシンサービスにデータベースなどを導入することで対応できます。
このように1つのサービスやクラウドの機能に制限されることなく、幅広い視野で考えれば、より良い環境が作れると思います。






