ギックスCEO網野 /取締役 花谷が【成果出す会社に学ぶデータサイエンス講座】に登壇(2014/6月)
日経情報ストラテジー主催のセミナーに株式会社ビューカードの会田雅彦常務取締役と共に、弊社網野と花谷が登壇しました。先日速報でお知らせした第3部のパネルディスカッション、第1部の講演録に続いて、第2部の講演内容をご紹介致します。
開催日時:2014年6月24日(火)13:00~14:25 「チームCMO」と1年で結果を出したビューカード 440万会員のビッグデータ分析で成果を出す
第2部 ビューカードでのマーケティング改革 発言録<速報版>
網野:
はじめまして。株式会社ギックスの網野です。
会田さんの話を聞いて、ここまで厳しい状況だと知っていたら、参画しなかったかもしれないなぁと思いました(笑)
とは言いつつ、一緒に面白いジャーニーを歩ませて頂いています。
本日お話したいのは、ビューカードさんの事例をお伝えしますが、まずは弊社がビッグデータを活用する際にどんなアプローチを取るのかという点もお話させていただければと思います。
1. 自己紹介 〜弊社は何者なのか?
2. 弊社が考えるビッグデータとは
3. ビューカードの取り組み
という流れで進めさせて頂きます。
1. 自己紹介 〜弊社は何者なのか?
GiXoは設立して1年半のスタートアップ企業です。私自身はアクセンチュア株式会社で戦略コンサルタントをしており、IBMではアナリティクス組織のリーダーを務めさせて頂いておりました。戦略とアナリティクスの両方のケイパビリティを軸に会社を立ち上げました。弊社はコンサルティングとアナリティクスを組み合わせて価値を提供するというサービスを行っています。

メインのサービスはチームCMOというサービスです。平たく言えば、CMOのロールを代行、又は支援するというサービスです。ビューカードの市川常務に新しくCMOというロールに就任頂いて、市川CMO含め、叶社長、会田常務をご支援させて頂くというサービスを提供しています。
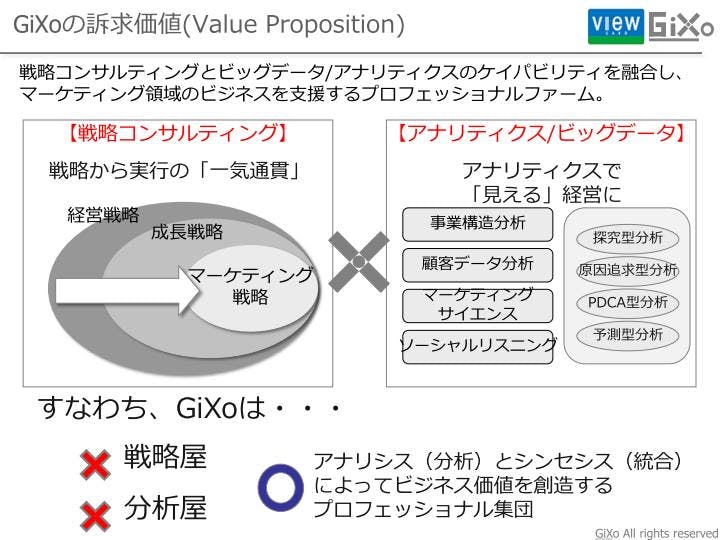
CMOと言うロールは大変な役職なので「お前らのような小僧に務まるのか?」というお話もあるかと思うのですが、さすがに一人ではできないので、弊社ではチームを組んで「チームCMO」というサービスを提供しています。CMOを支援/代行するにあたって必要なケイパビリティは4つあると考えております。
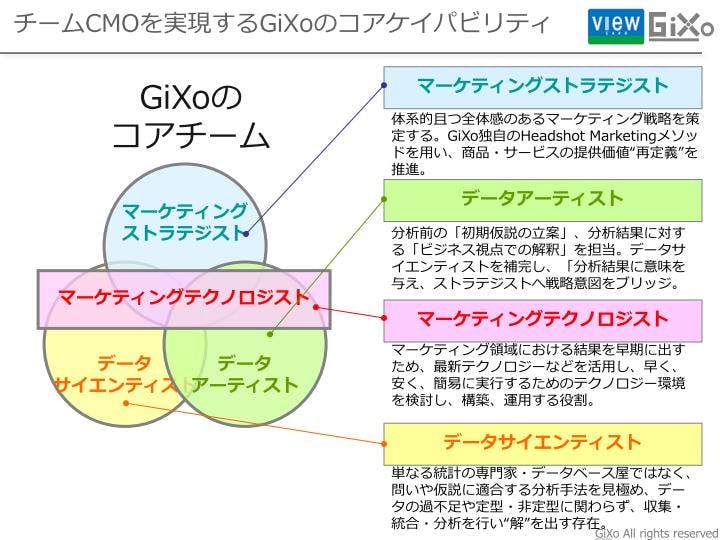
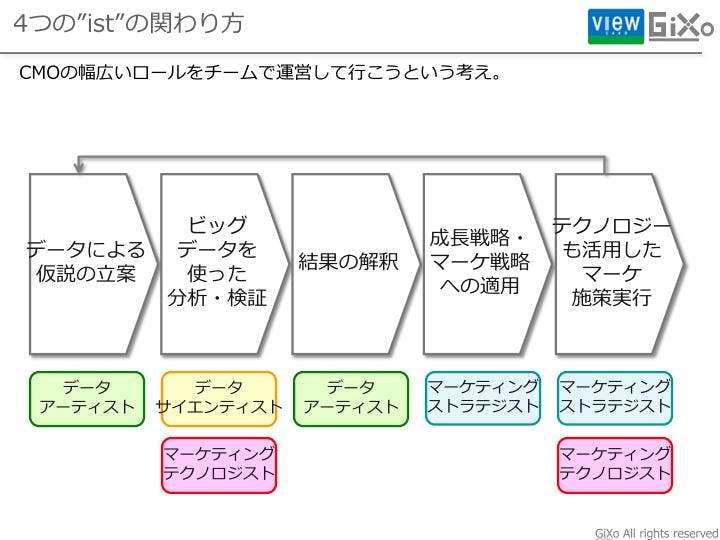
最近流行りのデータアーティストというロールだけではマーケティング領域の仕事には全く足りない。分析をする前の仮説立案や分析結果の解釈をデータアーティストが行いますし、解釈した結果を成長戦略につなげるマーケティングストラテジストという役割もあって初めてCMOの代行ができると考えております。
会場にもお越し頂いている日経情報ストラテジーの川又さんに弊社とビューカードさんの取り組みを記事にして頂きました。詳しくは弊社HPをご覧ください。
本日は時間もないので、ご紹介のみとさせて頂きますが、「会社を強くする ビッグデータ活用入門 基本知識から分析の実践まで」という本を出版しております。日経BPさんからの出版ではないので、この場でご紹介するのが少し心苦しいのですが(笑)。

2. 弊社が考えるビッグデータとは
ここからは、「弊社が考えるビッグデータとは」という内容について、お話を進めさせて頂きます。ビッグデータってなんだっけ?と言われても諸説ありますよね。私は20冊以上ビッグデータに関する本を読んだのですが、「ビッグデータとは?」の定義に対する答えは大きく4つの宗派あると思っています。

4宗派あるからと言って、何が正しいか間違っているかではないと考えいます。まとめ方や語り方の軸が異なるだけです。では、弊社ではどのようにビッグデータを捉えているかと言いますと、そもそも「データ活用の意味」を考えた時、データ活用は経営や事業の競争力向上につなげるるための活動ですよね。逆に言えば、データがビッグがリトルかはどっちでもいい話ですし、すごい分析か否かも関係ない。価値が出ればいいじゃないか、「データ量や分析の複雑さによらず、Big Out Comeをもたらすデータ活用がビッグデータ」というのが我々のスタンスです。

「ビックなアウトカムをもたらすデータ活用」を略して”ビッグデータ”と我々は呼んでいます。ですので、エクセルで処理できるデータ量であっても、経営や事業の競争力向上につながるのであれば、我々をそれを”ビッグデータ”と呼びます。
そう考えると、我々が考える”ビッグデータ”活用には2つの使い道があります。
1つ目は、「ここを強化するとうちの会社の収益が上がる」という自社の競争力強化、2つ目はビューカードさんでも支援させて頂いていることなんですが、PDCAを早く回していくこと、つまりPC(CA)∞サイクルです。

分析に関する業務や役職についている方が多いと思うので最初の戦略的活用のパートは非常に簡単に話します。まず初めに、「自社の競争力強化にビッグデータを織り込む」ことを説明する際に欠かせない二つの単語をご説明します。我々の造語で「儲け話のメカニズム」と「キードライバー」というものがあります。

「儲け話のメカニズム」と「キードライバー」が何なのかを明らかにし、どこを強くすれば、企業の競争力が向上するのかを理解した後に、そこに対してデータの活用を考えていきましょう、というのが「自社の競争力強化にビッグデータを織り込む」ということになります。私はamazonというより、ジェフ・ベゾスが相当好きでして、彼がファミレスの紙ナプキンに彼らで言うビジネスモデル、我々で言うメカニズムを記したのがこちらになります。
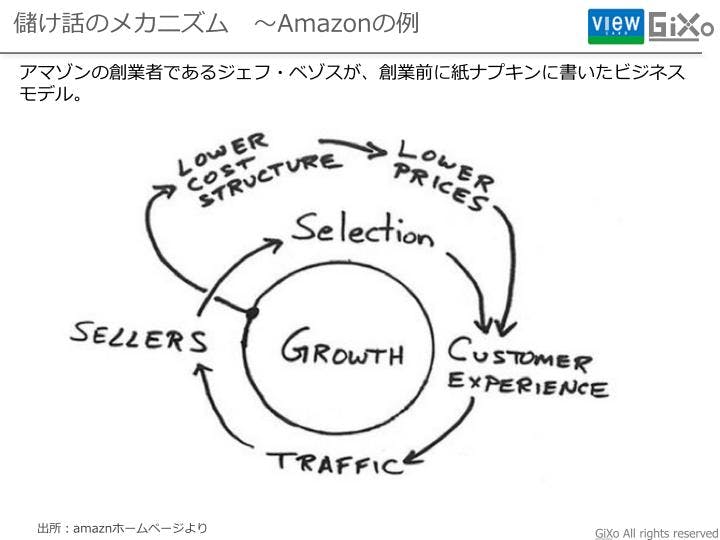
ジェフ・ベゾスが最もこだわったのは、「Customer Experience:顧客経験」すなわち、お客さんが”いい買い物したなぁ”と思ってもらえるようなことを軸に考え、そのために必要なものは、品揃えだと定義しました。品揃えがあれば顧客に購入してもらえる→トラフィックが増える→売りたいというsellerが増える→品揃えが更に増える→顧客経験が高まりまた購入してもらえる。このサイクルが回り続ければ成長していくことができると言うのはこの図で説明していることです。更に言えば、この手のプラットフォームビジネスは投資額は変わらないので、範囲の経済が効き、成長していくことで単位コストが下がり、ローワーコストストラクチャーという形になり、商品を安く提供していくことが可能になり、顧客経験が向上し、さらにサイクルが加速していきます。
こういったものがメカニズムだと思って頂ければと思います。
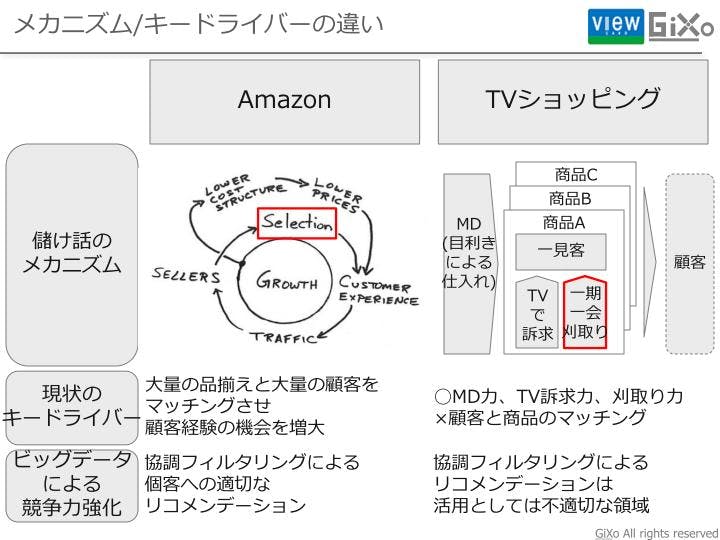
では、メカニズムをなぜ知っておく必要があるのでしょうか?amazonは協調フィルタリングという手法を活用したリコメンデーションが有名です。なぜamazonにとって、リコメンデーションが重要かというと、前述のメカニズムが回り、成長が加速していくことで膨大な顧客と膨大な商品がamazonに存在している時に、効率的かつ効果的に顧客と商品をつなぐ、マッチングする仕組みが必要であったからです。顧客経験を高めるために顧客にいい商品を買ってもらう、ということを実現する為にリコメンデーションを活用しているのです。収益性は二の次、顧客に良い経験・体験をしてもらいたいと考えるベゾフ氏ですから、クロスセルで単価を上げたい、売り込みたいというよりは、顧客に満足してもらいたい、あなたにあったいい商品があることを知ってもらいたいという思いが先にあってのことじゃないでしょうか。大量の顧客と大量の商品をマッチングさせることが彼らにとってのキードライバーになっているということです。キードライバーであるマッチングにビッグデータを活用することは、とても合理的な考えだと思います。
この協調フィルタリングが有名になった為に、多くの通販会社でいきなりデータ分析の手法から入って「リコメンデーションをやりたい」という依頼を受けることがあります。そのような依頼を受けると、「それは何のためなんだろう?」と考えてしまうんですよね。例えば、売れ筋商品が二桁もなく、全商品でも二桁中盤もないあるテレビショッピングを例に取ると、彼らのモデルは目利きのバイヤーがおもしろい商品を仕入れてきて、口だけだと良さが伝わらないので、映像に乗せて良さをを伝えているわけですよね。そして、顧客に欲しいと思って頂き、電話をかけてもらって、コールセンターで漏らさないように刈り取っていくという「いわば一期一会のお客様に対して、いかに離脱なく刈り取っていくか」が彼らのモデルなわけです。そう考えると、彼らが数百万人の顧客を抱えていたからといって、リコメンデーションをして意味があるかというとそうではないですよね。マットレスを買った人に高圧洗浄機をオススメしても買うかわかりませんし、むしろリコメンデーションよりは、コールセンターという顧客との最初の接点を大事にする、例えば、最初の会話でその顧客にあった対応を裏で分析を回してオペレーターに指示するような仕組みの方が効果があるように思います。いきなり競合のやり方を真似るのではなく、メカニズムとキードライバーを考えた時に自社が一番強くなるデータの使い方ってなんだろうねということを考えるべきですよね。
私の本のサブタイトルにもありますが、最近よく頂く問い合わせで「上司にいきなりビッグデータやれ!」って言われたという問い合わせを頂くのですが、そういう時はいきなり事例集めやモデル作りに入るのではなく、「そもそも私たちの会社の儲け話のメカニズムやキードライバーってなんだっけ?」ということを自分で考えるか、無茶を言ってきた上司に質問してみるといいと思いますよ(笑)

言われてみれば当たり前だと思われるかもしれませんが、ここを怠ると自分はおもしろくても会社にとってはインパクトのないビッグデータ活用になってしまいます。
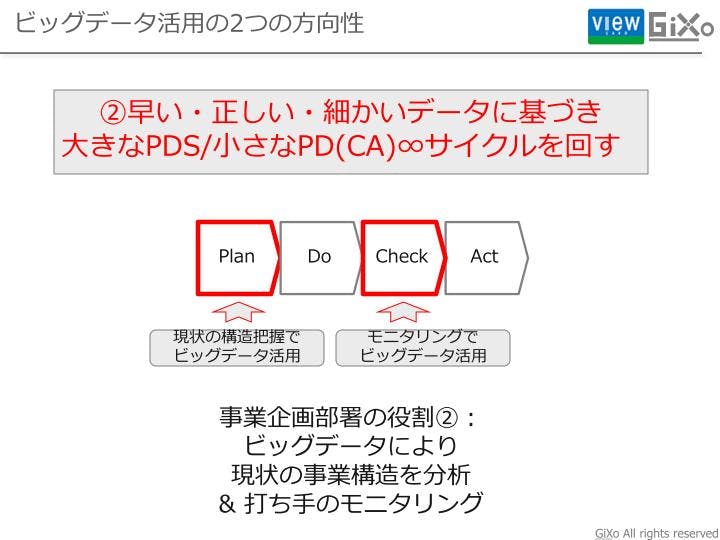
では、続いて2つ目の「早い・正しい・細かいデータに基づき大きなPDS/小さなPD(CA)∞サイクルを回す 」についてです。
ビッグデータブームのきっかけを考えると、テクノロジーの進歩によって、安価で簡易に大量データを分析できるようになったことにあると我々は考えています。私がアクセンチュアにいた2000年代後半だと、大量のデータをぶん回すには多大なコストがかかりました。会田さんがJR時代に一緒にプロジェクトをする機会がありまして、その時にやりたかった分析を行うには2億円程のハードウェアが必要でした。しかし、今は同じような分析を200万円程でできますし、クラウド環境を活用できるのであれば、200万円すらかからないという時代になりました。むしろそういったテクノロジーを使いこなせるかが鍵でもあると思っています。
現代のような大量データを簡単に扱える環境においては、PDCAの「Do:実行」は「Check」、「Action」をタイムリーに繰り返すことそのものが実行であると言えるので、下記のような図に構造が変わってきています。

意味のないことに「Check」と「Action」を実行しても仕方ないですよね。意味をのある打ち手を考える為には状況把握、事業構造を正しく理解して、事業計画や事業戦略を作って行くことが必要になります。では、事業構造はどのように理解すればいいのでしょうか?
我々は大量データを安価で簡易に回せる時代なので、トランズアクションデータ(取引明細)を手元においてエクセルを操作するように、顧客単位等の好きなメッシュで切ってしまえばいいと考えています。手元にトランズアクションデータを持つことで、色んな軸で簡易に顧客を分析をすることができ、事業構造を理解することに役立ちます。ビューカードさんは顧客単位で分析をしていますが、小売り業であれば売れ筋の商品といった軸で分析を行うや、B to Bであれば、誰が売ったか等の営業マン軸で分析をすることが可能になります。我々のようなベンチャー企業でもビューカードさんの2億件/年のトランズアクションデータ3年分、つまり6億明細ものデータを分析できるような環境を持つことができる時代になったので、分析環境を持つことへのハードルはかなり下がっています。

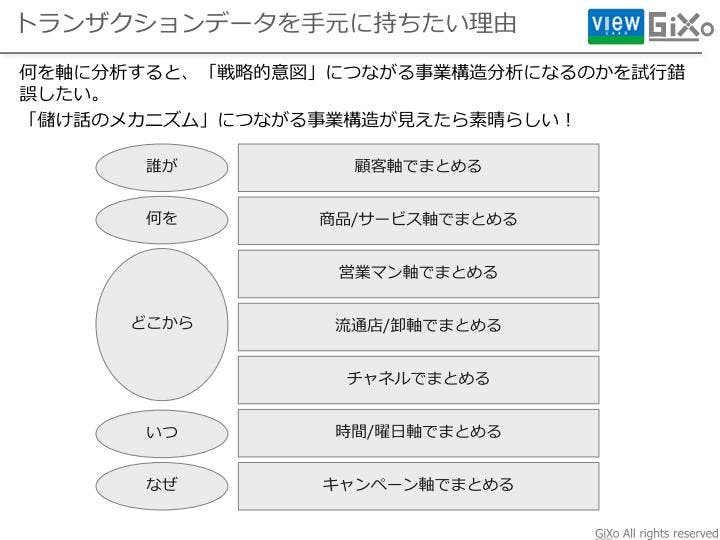
「戦略的意図」につながるような事業構造分析を行うために分析を突きつめていくと、結局はクロス集計に集約することが多いです。クロス集計は単純に見えるかもしれませんが、クロス集計でも多くの気づきを得ることができます。結局は事業の構造を見るには、○別の○別の○別の状況などと、軸毎に階層を切って行き事業構造を把握することになるからです。肝は、何をクロスで掛け合わせるかという点につきます。この切り口に知恵が必要です。我々はこれを2次属性データと呼んでいます。
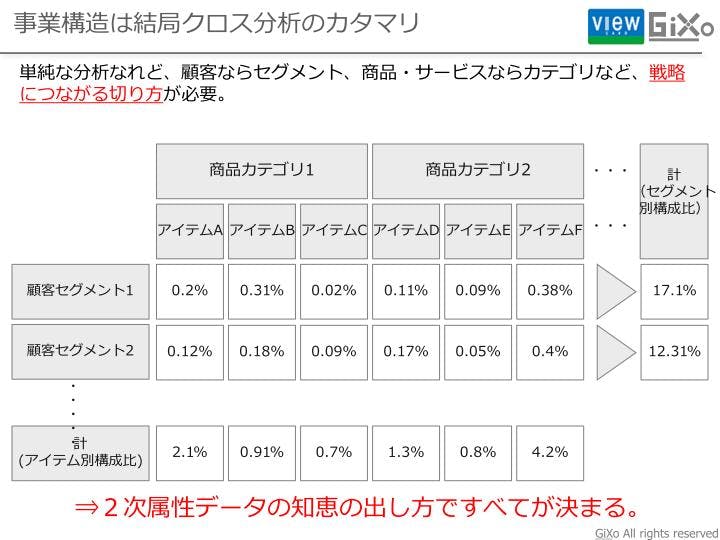

2次属性データとは、人間が後から解釈して付与したデータのことを意味します。典型的な例はRFM分析です。RFM分析も顧客毎にRecency、Frequency、Monetaryの各項目にスコアをつけて、1〜5の2次的な属性データを付けているだけにすぎません。RFM分析は人に2次属性をつけましたが、商品にも付与することが可能です。
イギリスのスーパーTescoは「商品DNA」という考え方に基づいて、商品に2次属性データを付与して、その2次属性データを用いて顧客のセグメンテーションをしています。ある商品に対して、「エコ」、「健康」等のフラグを付けて、それを購入した顧客はどういう人かを定義していいます。まあ、2次属性データと言うのは我々の呼び名であり、彼らはこれを2次属性データとは言っておりませんが(笑)。同じようなことを、顧客の価格志向という2次属性として付与することが可能です。この場合は商品の絶対額は重要ではありません。同じ1,000円でもワインは安いですが、チーズだと高級品になります。ワインならワイン、チーズならチーズの商品毎のプライスレンジの位置づけをフラグを設定することが2次属性データのフラグ付けです。このような価格帯フラグを設定したら、例えば会田さんという顧客は高価格帯の商品購入頻度が高い、よって顧客の価格志向を判断することができます。
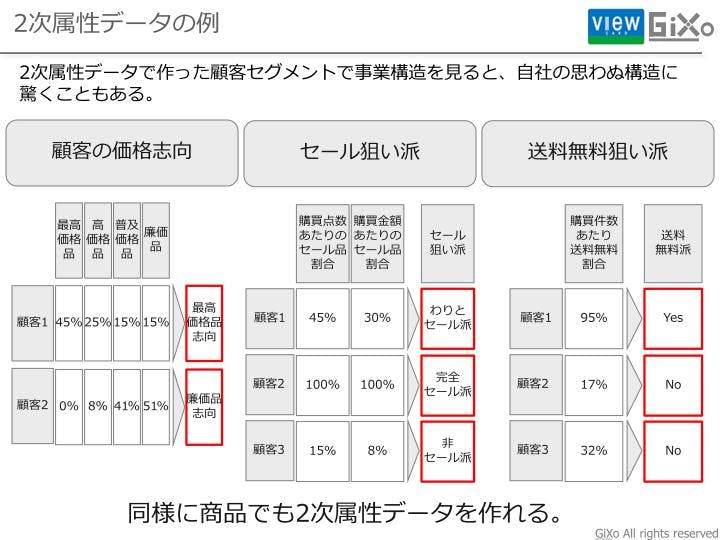
こういった分析を繰り返すことで、自社の事業構造が見えてきます。例えば自社の顧客は完全セール派とわりとセール派で売上の70%が占められているというような発見ですね。これがわかると、社長の方針が「セールからの脱却」であった時に、実際は売上の70%がセール派で占められていましたという事実と照らし合わせて、「さぁ、どうしますか」という議論ができます。もちろんデータを見ながら、「それでも、脱却する」が答えでもいいと思いますが、データを見ずに「セールからの脱却」という方針を掲げて、売上げが落ちたら驚いてすぐに撤回するのはマズいですよね。実は簡単に見えるクロス分析も頭を使った2次属性データを付与することで、自分たちの事業構造はどうなっていて、どんな顧客によって売上が占められているのかが理解できるのです。
一般的に使われている優良度の分析も、商品の買われ方から類推することでメイン利用といった顧客からのポジショニングという深堀りしたものになります。

2次属性はいくらでも付与できるので、ある意味では時間との戦いでもあります。自分たちの事業構造に関して、あたりをつけながら、分析を進めていくと単純の分析に見えますが、新たな気づきを得られるので是非試してみて下さい。
(後編に続く)
【成果出す会社に学ぶデータサイエンス講座:記事リスト】
- パネルディスカッション(ビューカード×ギックス)
- ビューカード会田常務 講演内容
- ギックス網野・花谷 講演内容(前編) 【当記事】
- ギックス網野・花谷 講演内容(後編)